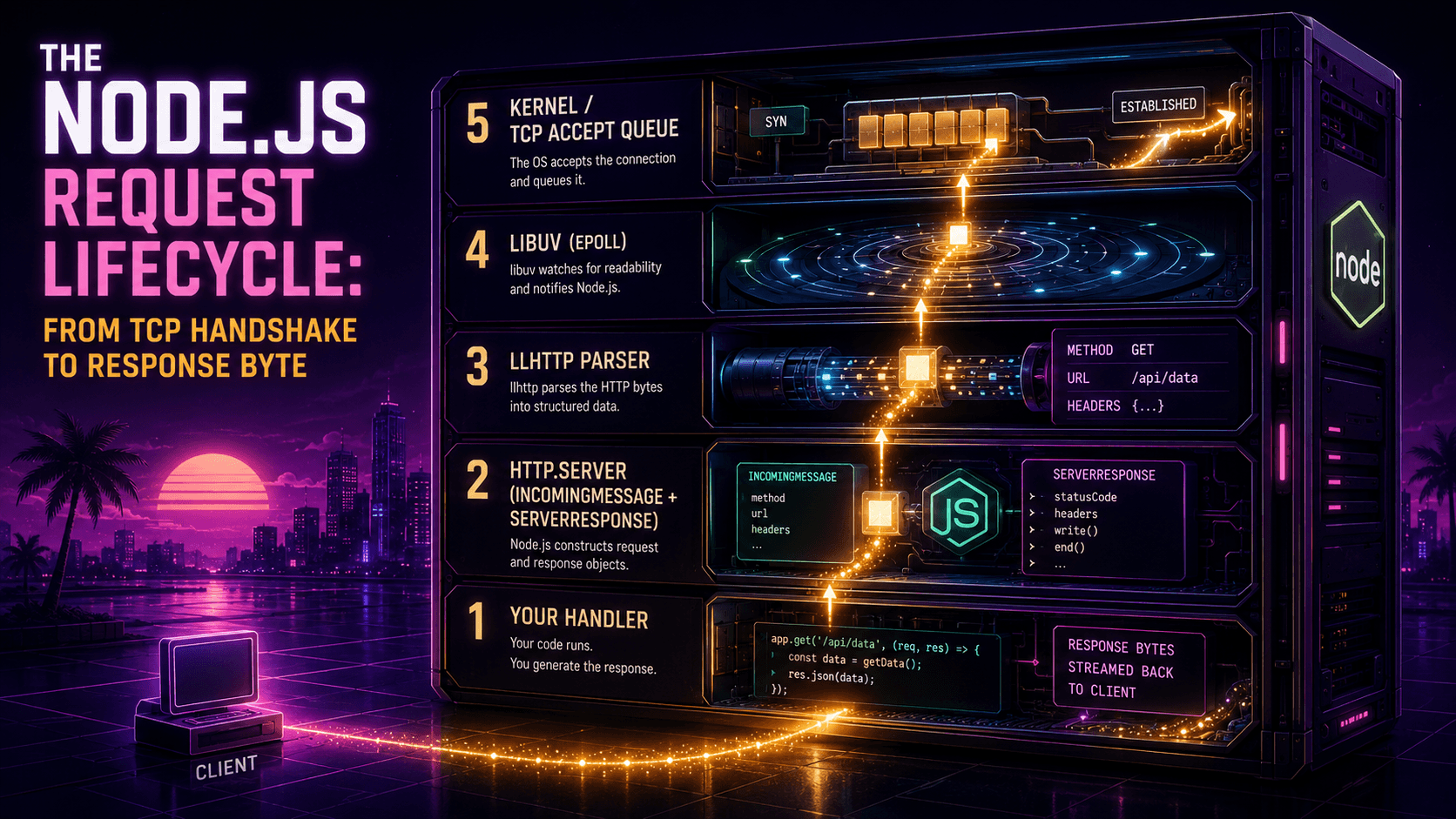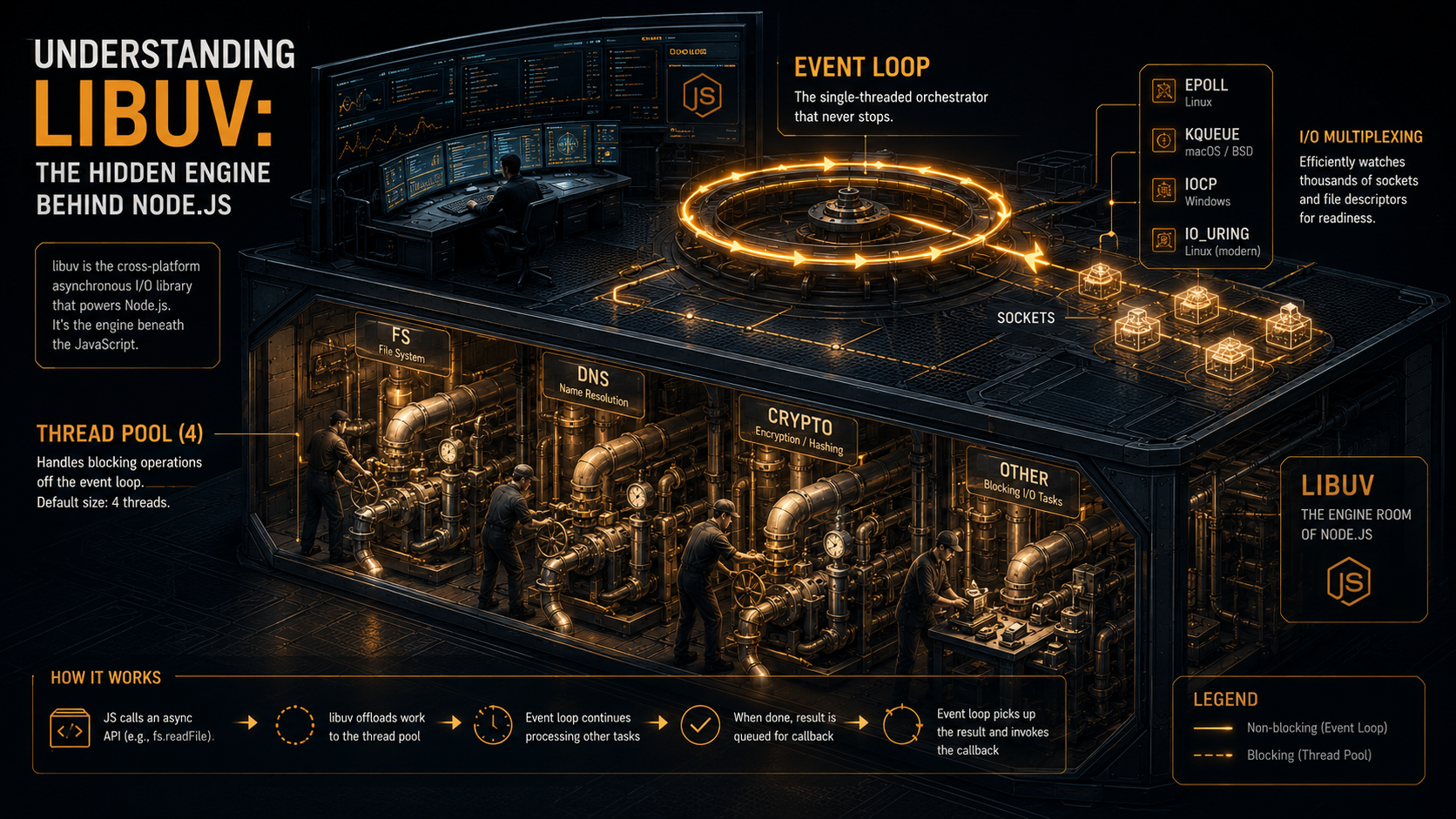
Open node on any machine, type process.binding('uv'), and you're staring at it. Not Chrome's V8. V8 doesn't know what a socket is. Not the standard library either: fs.readFile is a thin JS shim. The thing that actually talks to the kernel, schedules the event loop, runs the thread pool, and decides whether your await resumes in 200 microseconds or 200 milliseconds is a ~50,000-line C library called libuv. It is the most important piece of Node.js that almost nobody reads.
Most explanations of Node's async model stop at "there's an event loop and a thread pool." That's like explaining a car as "there's an engine and some wheels." Technically true, completely unhelpful. So let's go a layer deeper. We'll look at where libuv came from, what its event loop actually does on each tick, which operations hit the thread pool and which don't, why file I/O is the awkward stepchild of the whole design, and the handful of gotchas that bite people in production once a year, every year.
Where libuv came from (and why)
Node.js shipped in 2009 on Linux only, with an event loop borrowed wholesale from a C library called libev, plus libeio for async file I/O. Both were written by Marc Lehmann. They were excellent, for Linux. For Windows, they were nothing.
In 2011, Microsoft and Joyent funded a port of Node.js to Windows. The problem: Windows doesn't do epoll. Windows does I/O Completion Ports (IOCP), a completely different async model: "tell me when this completes" rather than "tell me when this is ready." You can't just #ifdef your way out of that gap. Ryan Dahl and Ben Noordhuis pulled the trigger and built a new abstraction layer called libuv, initially a wrapper around libev + libeio on Unix and IOCP on Windows. By Node v0.9, libev was gone entirely; libuv had its own epoll-based loop, and the dependency tree got a lot cleaner.
The name, by the way, means nothing. Noordhuis has said publicly that they made up "Unicorn Velociraptor" after the fact, because people kept asking. That's also the logo.
Today libuv runs on Linux (epoll), macOS / *BSD (kqueue), Windows (IOCP), Solaris/illumos (event ports), AIX (pollset), and, since libuv 1.45.0 in 2023, Linux io_uring as an opt-in backend for file I/O. It's used by Node.js, Deno (originally; Deno later forked some pieces), Luvit, Julia, neovim, and a long tail of language runtimes that needed a portable async layer and didn't want to write one.
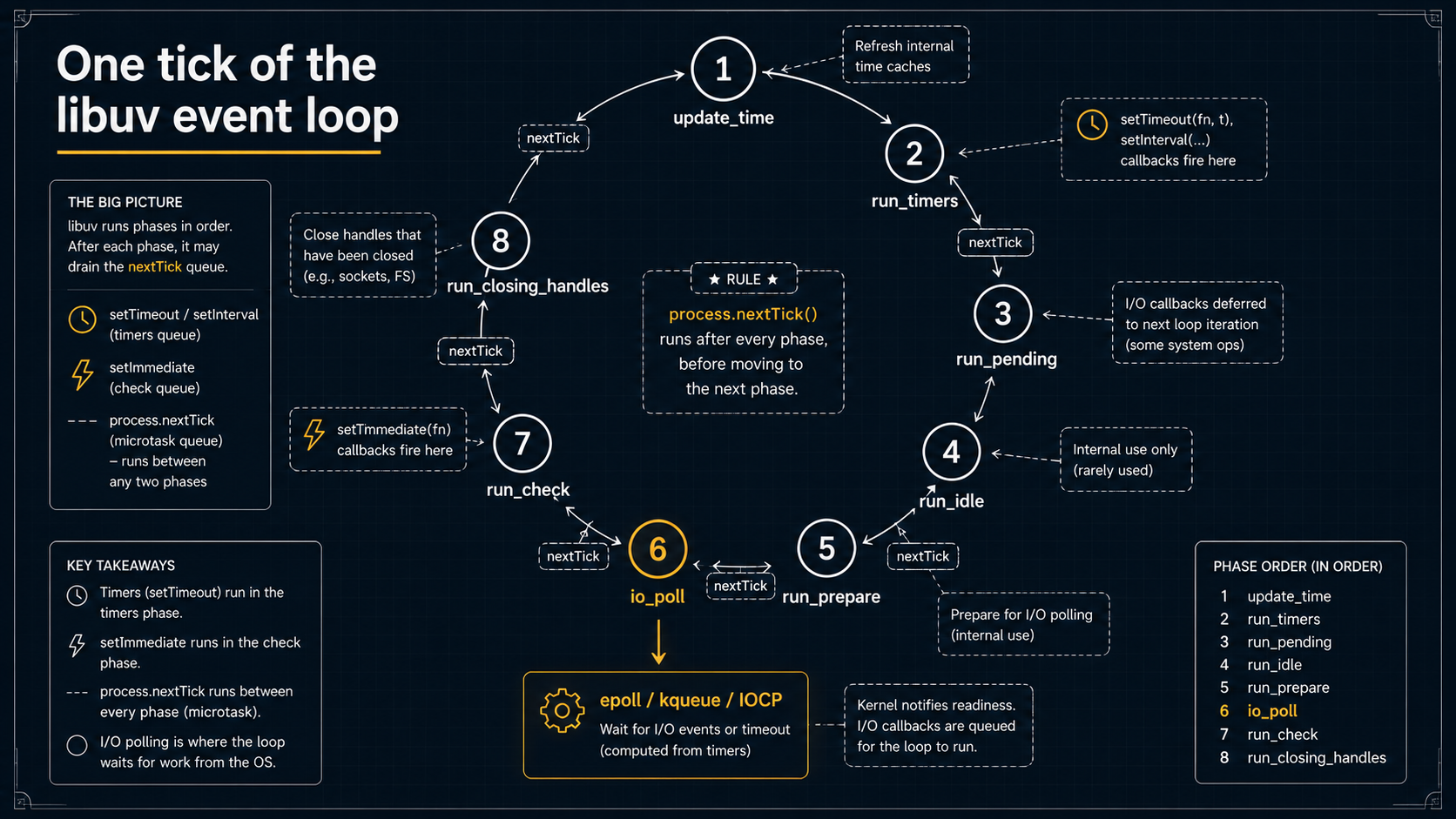
The event loop, phase by phase
The libuv event loop is a while (alive) { ... } in C. Each iteration is called a tick, and each tick walks through seven phases in a fixed order:
1. update_time // refresh "now" from the monotonic clock
2. run_timers // fire any setTimeout / setInterval whose time has come
3. run_pending // run I/O callbacks deferred from the previous tick
4. run_idle // idle handles (internal; rarely user-visible)
5. run_prepare // prepare handles (run before I/O poll)
6. io_poll // block on epoll/kqueue/IOCP for I/O events
7. run_check // check handles — setImmediate lives here
8. run_closing_handles // close callbacks for handles you uv_close()'dIf you've read the Node docs, you've probably seen a six-phase diagram that omits idle and prepare and merges update_time into timers. The Node docs simplify a little; libuv's src/unix/core.c is the source of truth. The diagram above matches what uv_run() actually does.
A few things worth pinning down, because they're the source of half the confusion in this area:
process.nextTick and Promise microtasks do not live in any of these phases. They run between every callback, drained completely before libuv hands control back. That's why a busy loop of process.nextTick(fn) will starve I/O and timers: you never let libuv reach the poll phase. This is V8 + Node, not libuv.
setImmediate runs in the check phase, after io_poll. setTimeout(fn, 0) runs in the timers phase, before io_poll. If you're inside an I/O callback, setImmediate always wins. If you're at the top level, the order is a coin flip: whichever phase the loop happens to enter first. Crazy, right? But once you see the phase order, it's obvious.
Close callbacks run dead last. When you do socket.destroy() and pass a callback to socket.on('close', ...), that callback fires in phase 8, after everything else on that tick. If you're trying to chain "close this server, then exit" logic, that's the order you're working with.
Handles and requests: the two abstractions everything else is built on
libuv has exactly two kinds of objects, and once you internalize the difference, the API stops feeling like a grab bag:
- A handle is a long-lived thing. A TCP server, a TCP socket, a timer, a signal listener, a child process, a TTY, a UDP socket. They're all handles. Handles have lifecycles: you init them, they fire callbacks over time, you
uv_close()them.uv_handle_tis the base type. - A request is a short-lived in-flight operation. Reading a file, resolving a DNS name, writing a buffer to a socket, calling
pbkdf2. They're all requests. A request fires its callback exactly once, then it's done.uv_req_tis the base type.
The reason this matters in JavaScript-land: when you keep getting "Why won't my Node process exit?", the answer is almost always an open handle you forgot about. process._getActiveHandles() and process._getActiveRequests() (both undocumented but stable enough that everybody uses them) will print exactly what libuv is still tracking. A stray setInterval, an open server socket, a connected net.Socket: anything in those arrays is a handle keeping the loop alive. unref() exists for exactly this reason: it tells libuv "don't count this handle when deciding whether the loop has work."
The thread pool: the part that confuses everyone
Here's the line that wrecks people: the event loop is single-threaded, but Node is not. libuv ships with a thread pool, four worker threads by default, and a surprising amount of "async" in Node actually means "a worker thread does it synchronously, then posts the result back to the loop." The official libuv docs are explicit: the default is 4, you can raise it via UV_THREADPOOL_SIZE up to 1024 (raised from 128 in libuv 1.30.0), and the threads are pre-created lazily on first use.
What actually uses the thread pool? It's a smaller list than you'd think:
fs.* (almost everything — readFile, writeFile, stat, ...)
dns.lookup() (via getaddrinfo, which is blocking glibc)
crypto.pbkdf2
crypto.scrypt
crypto.randomBytes / randomFill
crypto.generateKeyPair
zlib.* (deflate, gunzip, etc.)
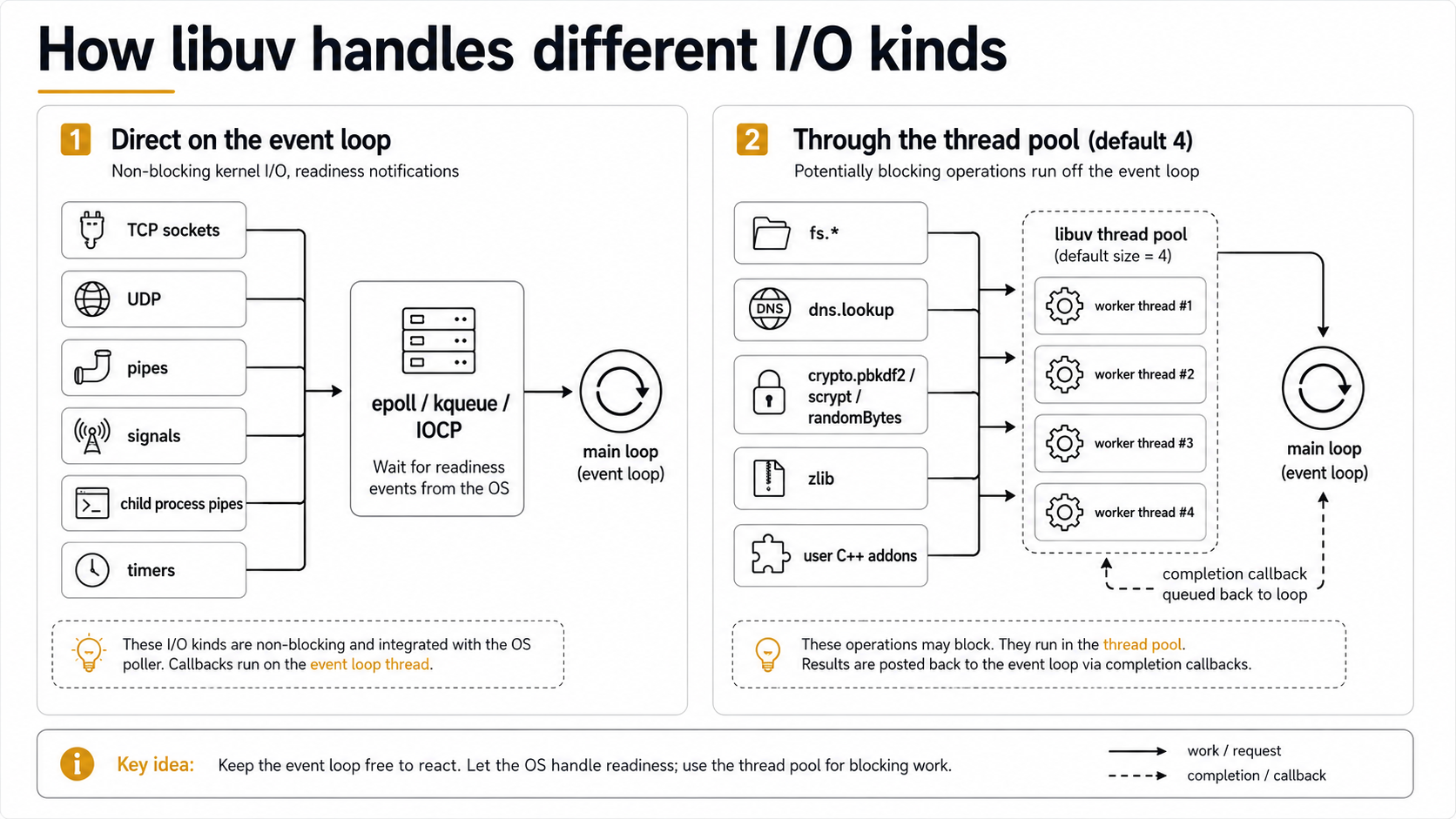
your own C++ addons (via uv_queue_work)That's it. Everything else, TCP, UDP, pipes, TTY, signals, child process I/O, timers, does not touch the thread pool. They run directly on the event loop using epoll / kqueue / IOCP.
This is the source of the most common production bug in this area: a Node process that suddenly stalls under load because every worker thread is busy doing crypto.pbkdf2 for password hashing. With a default pool size of 4, four concurrent logins will saturate the pool. The fifth login waits in a FIFO queue until one finishes. The fs.readFile your request handler issued? Also queued, behind the password hashes. Now your latency P99 looks like a brick.
The fix is rarely "raise the pool size to 64." The fix is usually "don't put a CPU-bound operation on the request hot path," or "do password hashing in a worker thread / a separate service." Raising the pool size moves the cliff, but it doesn't remove it, and every worker thread has a real memory cost (~8 MB stack by default on Linux). Bumping it to 1024 because you can is how you eat a few gigabytes for no reason.
Network I/O: the part that doesn't use threads
When you do server.listen(3000) and a client connects, no thread pool is involved at any point. libuv registers the listening socket with the kernel's readiness API and goes back to sleep. When the kernel says "this socket is readable," libuv wakes up in io_poll, calls your connection handler, and that handler runs on the main thread.
The readiness API depends on the OS:
| OS | API | Style |
|---|---|---|
| Linux | epoll |
readiness ("this fd is now readable") |
| macOS, *BSD | kqueue |
readiness |
| Windows | IOCP | completion ("this read finished, here are the bytes") |
| Solaris / illumos | event ports | readiness |
| AIX | pollset / poll | readiness |
The readiness-vs-completion split is why libuv's internals look the way they do. On Unix, libuv waits for the kernel to say "go ahead," then issues the syscall itself. On Windows, libuv issues the syscall up front, asks for a completion notification, and the kernel hands back the data when it's done. From the outside they look the same: socket.on('data', ...) fires either way. But the work libuv has to do to paper over the difference is enormous. Most of src/win/ is exactly that.
The practical upshot: a single Node process can hold tens of thousands of idle TCP connections at near-zero CPU cost, because none of them is occupying a thread. Each one is just an fd registered with epoll. This is the entire reason Node was a big deal in 2010: Apache's prefork was burning one process per connection, and Node was burning one fd. The math was decisive.
File I/O: the awkward special case
Here's the asterisk on everything above: the kernel does not have good async file I/O on Linux, or at least, it didn't for libuv's entire first decade. Linux's aio_* family is incomplete and buggy on most filesystems; the venerable advice has always been "don't use it." So libuv took the only option available: it does file operations on the thread pool, synchronously, and posts the result back. When you write await fs.promises.readFile(...), you are paying for a thread to call read(2) for you and a context switch to deliver the bytes.
This is fine for most workloads: disk is fast and you rarely have more concurrent file ops than thread pool slots. But it explains a few weird behaviours:
- File I/O contends with crypto. Same pool, same FIFO. A burst of
fs.readFilewill queue behind a slowpbkdf2. - File I/O on Windows is the opposite. IOCP supports true async file I/O, so on Windows libuv uses it natively and the thread pool isn't involved for most file ops. Your portable code has different bottlenecks on different OSes. Surprise.
fs.readFileSyncdoes not use the pool. It blocks the event loop directly. Calling it inside a request handler is the classic "my server stops responding" bug.
In 2023, libuv 1.45.0 added optional support for Linux io_uring, which finally gives the kernel a proper async file I/O interface. Node.js shipped it enabled in 20.3.0 / 20.4.0, then disabled it again a few months later when a security advisory landed: io_uring lets a process bypass certain seccomp filters and was being abused in CVEs against container runtimes. It's still in the libuv source today, but gated behind UV_USE_IO_URING=1, and Node has flipped the default a couple of times depending on the release. If you're running Node in a sandbox, you almost certainly want it off.
The takeaway: file I/O on Node is async from your code's point of view, but the mechanism behind the scenes is "a thread did it for you." That distinction stops mattering at small scale and starts mattering a lot once you're issuing thousands of file ops per second.
DNS: the trap nobody tells you about
dns.lookup('example.com', cb) looks like network code. It is not. It calls getaddrinfo(3), which is a blocking glibc function that reads /etc/resolv.conf, talks to nscd if it's running, and may walk through /etc/hosts. Because it's blocking, libuv shoves it onto the thread pool.
So dns.lookup competes with fs.readFile and crypto.pbkdf2 for the same four worker threads. If your DNS server is slow (say, a misconfigured corporate resolver, or the AWS metadata service under load), every concurrent lookup ties up a pool slot until it returns or times out. With four threads and a slow DNS server, you can hang the entire async I/O subsystem of your process with five HTTP requests.
The Node standard library has a second DNS API, dns.resolve* (e.g., dns.resolve4), that uses c-ares, a pure-async DNS resolver bundled with Node. c-ares talks to nameservers directly over UDP via libuv's network sockets, never touches the thread pool, and never blocks. It's almost always what you actually want for outbound HTTP clients.
The catch: http.request and https.request use dns.lookup by default, not dns.resolve. So your HTTPS client is putting blocking DNS calls on the thread pool whether you asked for it or not. To switch a Node HTTP client to async DNS, you pass a custom lookup function to the agent that uses dns.resolve under the hood, or use an Agent like cacheable-lookup, which a lot of high-throughput services in the wild do exactly because of this.
This single fact has been the root cause of more "why is my Node service flaky under load" incidents than I can count. The Node docs mention it; nobody reads that page.
Timers, signals, child processes: the small handles
A few more pieces of libuv worth a glance, because they're handles you use every day without thinking about them:
Timers. libuv keeps timers in a min-heap keyed on absolute fire time. Each tick, after updating now, it walks the top of the heap and fires anything that's due. The complexity is O(log n) per insert and O(1) per peek, which is why a Node process can have a million active timers without breaking a sweat, but it's also why setTimeout(fn, 0) is not actually zero; libuv clamps to 1 ms minimum.
Signals. On Linux, libuv catches SIGINT, SIGTERM, etc. via signalfd and turns them into events on the loop. That's how process.on('SIGTERM', ...) works without you having to worry about reentrant signal handlers: by the time your JS callback runs, you're already back on the loop, not in a signal context. (SIGKILL and SIGSTOP can't be caught, of course; that's a kernel rule, not a libuv one.)
Child processes. When you child_process.spawn, libuv forks, dup2s the pipe fds, and execvps the new program. Stdin/stdout/stderr become uv_pipe_t handles on the parent side, which means the child's output is read with the same mechanism as a TCP socket. There's no special "child process I/O" code path: it's pipes all the way down.
Gotchas, in one list, sorted by how often they bite people
crypto.pbkdf2/bcrypt/scrypton the request path will eat your thread pool. With 4 workers and 100ms hashes, you can serve 40 logins per second total, fewer if anything else is also using the pool. Move hashing to a worker thread, a queue, or a dedicated service.dns.lookupblocks a pool thread. Usedns.resolve*orcacheable-lookupfor HTTP clients that fan out.fs.readFileSyncblocks the event loop. No pool, no async. The whole process stops until the read returns. Acceptable at startup; never at request time.process.nextTickand Promise microtasks starve the loop. A recursiveprocess.nextTick(fn)will never let libuv reachio_poll. Your server will stop answering requests while CPU sits at 100%. UsesetImmediateif you need to yield.- A forgotten
setIntervalkeeps the process alive.process.exit()is the nuclear option;.unref()is the surgical one. - Raising
UV_THREADPOOL_SIZEwon't help if the bottleneck is CPU-bound. You're trading one queue for one queue plus 60 idle threads. setImmediatevssetTimeout(fn, 0)order depends on where you are in the loop. Inside an I/O callback,setImmediatewins. At top level, it's a race. If the order matters, usesetImmediateexplicitly.
What this means in practice
You don't write libuv. You don't even import it. But every async API in Node is a thin wrapper around it, and almost every weird performance bug (the kind where the code looks fine, the metrics look fine, and the latency P99 is on fire) has a libuv-shaped explanation lurking underneath. The four-thread pool is the most common culprit, but it's not the only one: the readiness-vs-completion split, the timer min-heap, the way close callbacks fire dead last on the tick, the fact that DNS lookup is secretly file I/O, all of these can show up in production and look like magic if you don't know the layer below.
The good news is that the layer below is small and stable. libuv has had the same architecture for over a decade. Read src/unix/core.c for an afternoon: it's well-commented C, no clever metaprogramming, no surprises. You'll come out the other side with a much sharper mental model of what await actually does between the time it suspends and the time it resumes. And you'll never confuse dns.lookup with dns.resolve again.
That's worth a lot more than memorising the event loop diagram.