
Have you ever watched a team confidently split their monolith into eight services, only to discover six months later that they can't deploy any of them independently?
You've probably been on that team. Or you've watched a company at fifty engineers debate "should we go microservices?" for nine months, then ship one anyway because the org chart already split into product squads and nobody wants to share a repo.
Both of those stories are about the same thing.
Microservices aren't really an architecture decision. They're an organizational one. The architecture is just where the bill comes due.
So let's talk about what you're actually paying for, what you're actually getting, and the four places it usually goes wrong: boundaries, deployment independence, data ownership, and observability.
What Problem Are You Actually Solving?
You don't adopt microservices because your code is too slow. CPUs are fast. Networks aren't.
You adopt microservices because the team is too big to fit in one repo without stepping on each other every day.
That's a real problem. If you have forty engineers committing to one Rails app, you'll feel the pain: slow CI, scary merges, deploy queues, a release calendar that looks like an air-traffic-control board. Microservices solve that by drawing fences. Each team owns its fence.
But the fences cost you. Latency, complexity, observability tooling, deploy pipelines, on-call rotations, schema coordination. None of it is free. Before you reach for the pattern, ask the honest question: which of those costs are you willing to pay, and what are you getting in return?
The honest framing is closer to taxation than to design. You're paying complexity to buy team autonomy. Sometimes that trade is great. Sometimes you're paying tax for a service the government doesn't actually deliver.
Boundaries Are The Entire Game
A microservice without a real boundary is just a function call with extra steps.
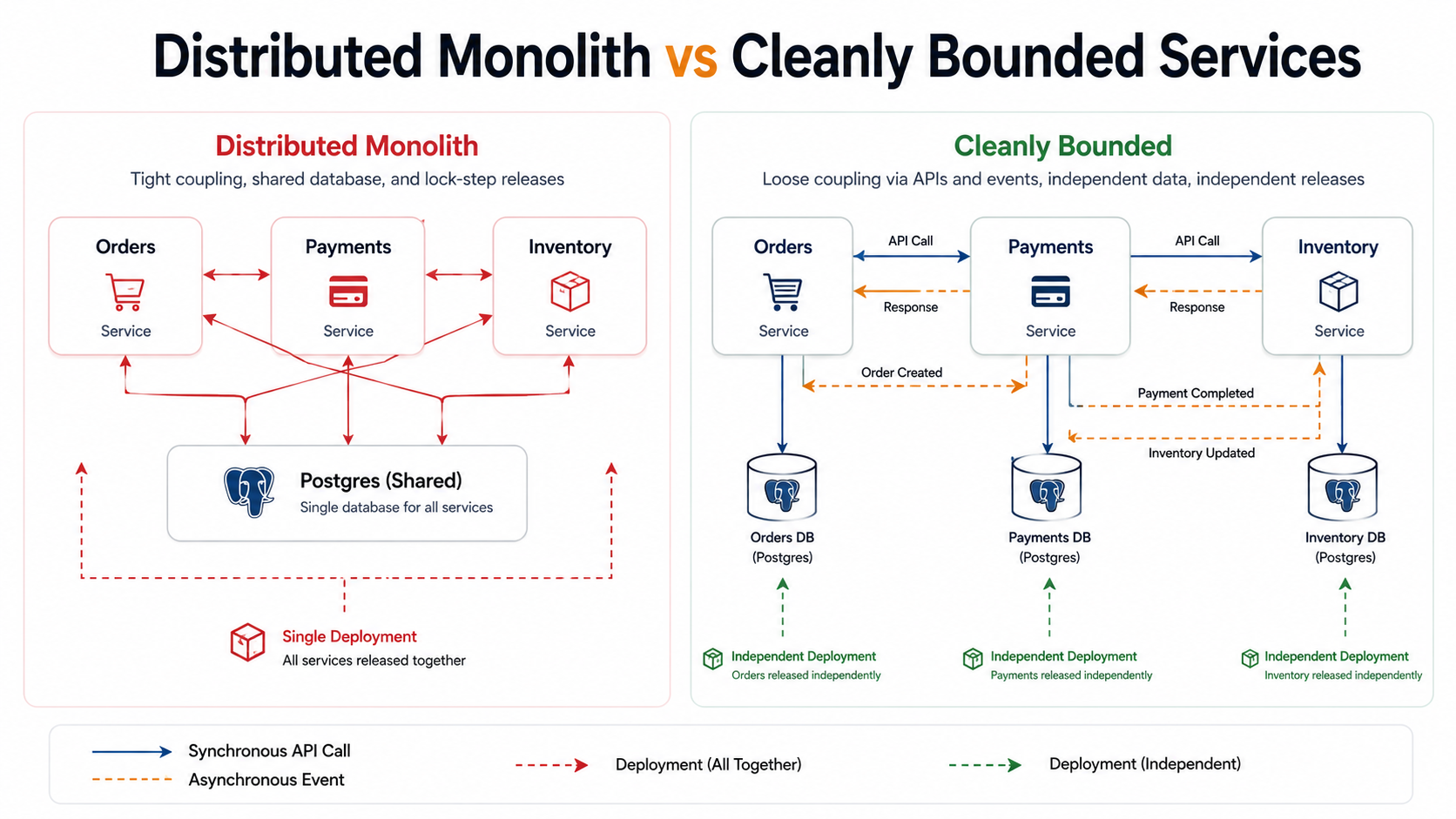
The smell is easy to spot: any time you change service A, you also have to change service B, and you ship them as a pair. You've drawn the line in the wrong place. You've built a distributed monolith. You're paying the network tax without the deployment-independence prize.
Good boundaries follow business capabilities, not technical layers. "Orders" is a boundary. "Inventory" is a boundary. "Database access" is not, that's a layer, and a layer dressed up as a service is one of the most expensive mistakes you can make. So is "the Auth microservice that every other service calls on every request," and that's a function turned into a hop.
Here's the test. If this service had to be rewritten in a different language by a different team next year, would the rest of the system survive? If yes, the boundary is real. If no, it's cosmetic.
func CreateOrder(w http.ResponseWriter, r *http.Request) {
var input CreateOrderInput
if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
http.Error(w, "bad input", http.StatusBadRequest)
return
}
// Reserve stock by calling Inventory's public API — never by reaching into its DB.
if err := inventory.Reserve(r.Context(), input.SKU, input.Quantity); err != nil {
http.Error(w, "out of stock", http.StatusConflict)
return
}
order := orders.Create(input)
json.NewEncoder(w).Encode(order)
}That inventory.Reserve call is doing the real work of the boundary. The Orders service doesn't know how Inventory stores stock counts, doesn't share its tables, doesn't even know which language Inventory is written in. It knows the contract.
The moment you reach into another service's database (directly, "just for this one report"), you've crossed the boundary, and you've quietly turned two services into one again.
Deployment Independence Is The Real Prize
Here's the only honest reason to pay the microservices tax: you want each team to ship without coordinating with the others.
That's the entire point. If your services deploy together, are released together, and the build pipeline ties them with one big knot, you have not gained deployment independence. You've gained a bigger build pipeline and a worse debugging experience.
The bar is unglamorous. Can you push a change to the Payments service today, on a Tuesday afternoon, without paging the Orders team or the Inventory team or anyone else?
If yes, you have microservices. If no, you have a distributed monolith.
The version-coupling test is brutal. If your Orders service v1.4.0 only works with Payments v2.1.0, and you ship them as a pair, you have a monolith with extra hops. The fix isn't deeper integration testing. The fix is contract discipline:
- Services communicate over versioned APIs: paths, headers, or message schemas.
- New fields are additive. Removing fields is a multi-step deprecation: add the new, dual-write, migrate consumers, drop the old.
- The producer is responsible for not breaking consumers. The consumer is responsible for being tolerant of unknown fields.
apiVersion: apps/v1
kind: Deployment
metadata:
name: payments
labels:
app: payments
version: "2.1.0"
spec:
replicas: 4
template:
spec:
containers:
- name: payments
image: registry.example.com/payments:2.1.0
readinessProbe:
httpGet: { path: /healthz, port: 8080 }That manifest belongs to one team. Their CI builds it. Their on-call rotation owns it. Their release cadence is whatever their release cadence wants to be: daily, weekly, three times a quarter. The other teams shouldn't notice.
If they do notice, you don't have microservices yet. You have shared infrastructure with extra YAML.
Data Ownership Is Where It All Falls Apart
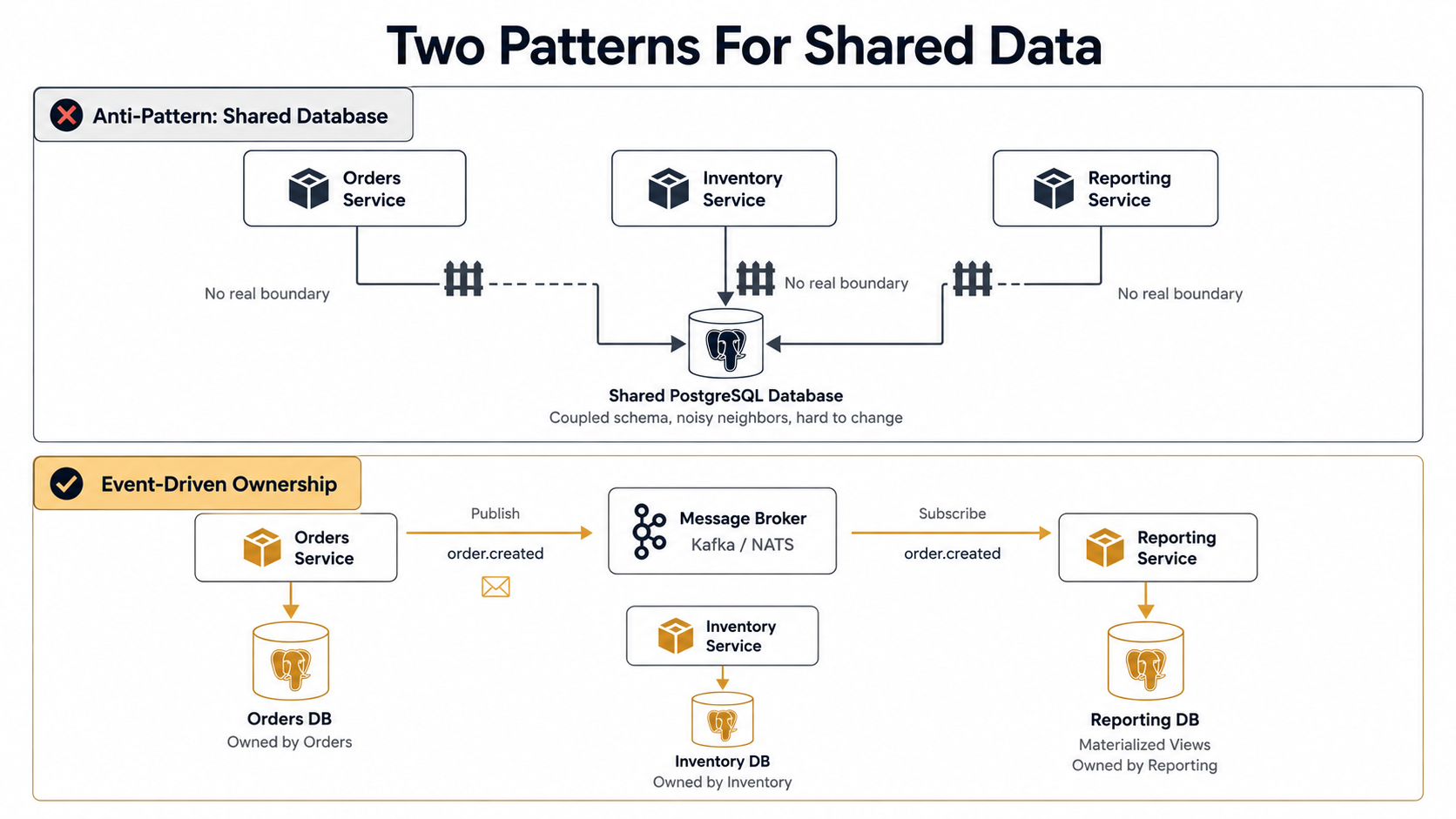
Most distributed monoliths share one root cause: they share a database.
It's the most common shortcut. "We're going to split the services, but we'll keep the same Postgres for now." Six months later, every service has migrated its part of the schema, every service knows the others' table names, and you can't deploy anyone independently because a column rename in orders breaks the Inventory service in production.
The rule is unforgiving but simple: each service owns its data, period. Other services can't read it, can't write it, and ideally can't even know what tables exist. They get to ask via the public API or subscribe to an event.
Here's the pattern that quietly destroys microservice projects:
-- Reporting service reaches into multiple services' tables
SELECT
o.id,
o.total,
u.email,
i.warehouse_code
FROM orders.orders o
JOIN users.users u ON u.id = o.user_id
JOIN inventory.stock i ON i.sku = o.sku
WHERE o.created_at > now() - interval '7 days';That JOIN is doing more damage than any other line of code in the system. It glues three "services" into one schema. The moment someone in Orders renames total to total_cents, Reporting falls over in production. The teams now have to coordinate every migration. Welcome back, monolith, and now with worse latency.
The replacement isn't pretty. It's distributed. Each service publishes events about its own data. Other services consume those events and build their own local view of the world.
{
"type": "order.created",
"version": 1,
"occurred_at": "2022-02-10T14:20:01Z",
"payload": {
"order_id": "ord_8a23",
"user_id": "usr_77f1",
"sku": "BOOK-COFFEE-101",
"quantity": 2,
"total_cents": 4998
}
}Reporting subscribes to that event and writes its own row in its own database. If Orders renames total to total_cents, the event payload version bumps, Reporting handles both versions during a deprecation window, and life goes on. Coordination shrinks from "agree on every migration" to "agree on the contract".
Yes, this is more work. Yes, eventual consistency is a real cost. Reporting will be a few hundred milliseconds behind. Yes, you'll occasionally have to backfill from a snapshot when a consumer falls behind. But the cost of the alternative is that you bought a microservice architecture and got a shared-database monolith with extra latency. That's the worst of both worlds.
If you can't bring yourself to split the database, you probably shouldn't be splitting the services yet either. Database-per-service isn't a "nice to have eventually." It's the load-bearing wall of the whole pattern.
Observability Is No Longer A Nice-To-Have
In a monolith, you have one process, one stack trace, one log file. When something breaks, you read it.
In a microservice architecture, a single user request fans out through five services, three queues, and two databases. There's no single stack trace. There's no single log file. If you don't have distributed traces, structured logs, and a way to correlate a request across hops, you don't have a debuggable system. You have a black box that occasionally times out at 3am.
The minimum bar is:
- A trace ID generated at the edge and propagated through every hop, in every protocol: HTTP headers, gRPC metadata, message envelopes, the lot.
- Structured logs that include that trace ID on every line, in every service.
- A trace store that lets you look up "what did this one request actually do" and see the full graph.
The propagation is non-negotiable. If even one service forgets to forward the trace headers, the trace ends there and you're guessing again.
import logging
from contextvars import ContextVar
trace_id_ctx: ContextVar[str] = ContextVar("trace_id", default="-")
def trace_middleware(get_response):
def middleware(request):
traceparent = request.META.get("HTTP_TRACEPARENT")
trace_id = parse_trace_id(traceparent) if traceparent else generate_trace_id()
trace_id_ctx.set(trace_id)
response = get_response(request)
response["traceparent"] = build_traceparent(trace_id)
return response
return middleware
class TraceFilter(logging.Filter):
def filter(self, record):
record.trace_id = trace_id_ctx.get()
return TrueEvery log line that filter touches now carries the trace ID. Every outbound HTTP call should forward the header. Every queue message should serialize it into the envelope. Skip any one of those and a debugging session goes from "fifteen minutes" to "we'll need to ship a build with extra logging and try again tomorrow".
OpenTelemetry is the boring, correct answer here. It's the standard, every major language has a stable SDK, and most observability vendors speak OTel natively: Jaeger, Tempo, Honeycomb, Datadog, New Relic, take your pick. Pick a backend that fits your budget, wire OTel through every service, and call it a day. The mistake teams make is treating observability as something to add later. Later is when you have an incident and no idea where the request died.
Without that wiring, microservices stop being an architecture and start being an exercise in trust.
When The Tax Is Worth Paying
Microservices pay off when several conditions are true at once:
- You have multiple teams that genuinely need to ship at independent cadences. Not "would prefer to," but actually need to. Two teams blocking each other on every release is a real organizational cost.
- The boundaries map cleanly onto distinct business capabilities, not arbitrary technical slices.
- You have, or can build, the operational scaffolding: container orchestration, distributed tracing, structured logging, schema-evolution discipline, a CI/CD setup that supports independent deploys.
- You're prepared to enforce data-ownership boundaries even when "just one cross-service JOIN" looks tempting at 5pm on a Friday.
- The latency budget tolerates the extra hops, or you've designed the contracts to be coarse enough that hops are infrequent.
If most of those are true, microservices give you something a monolith can't: the freedom for independent teams to move at their own pace without coordinating every commit. That's a real prize.
If only some of those are true, you'll pay the tax and not collect the benefit. You'll get the latency, the deploy complexity, the observability burden, the schema-coordination meetings, and you'll still be deploying everything together because the boundaries weren't real.
If none of them are true (small team, single product, one release cadence), a well-organized monolith is almost certainly the right answer. Modules, packages, clear seams. You can split it later when the org demands it. You can't easily merge eight microservices back together when you realize you didn't need them.
A useful intermediate step gets ignored too often: the modular monolith. One deploy unit, hard module boundaries, no cross-module database access. Most of the architectural benefit, none of the operational tax. When the org actually needs independent deploys, the seams are already there to extract a service along.
Microservices are a tax. Sometimes the tax is worth paying. Sometimes it's not.
The tax buys you organizational independence: different teams shipping at different cadences without tripping over each other. That's the real prize, but only if you actually need it and only if you're willing to pay the bill: real boundaries, real deployment independence, real data ownership, real observability.
Skip any one of those, and you've paid the tax without receiving the goods.
So before the next architecture meeting, ask the boring question first: what organizational problem are we solving here, and is splitting the codebase the cheapest fix? Sometimes it is. More often than people admit, it isn't.
Either answer is fine. Just be honest about which one you're making.





