So, you've heard the line: "MongoDB is schemaless."
And you've probably also heard the follow-up six months later, when somebody on the team says "why is this collection a dumpster fire?"
Both things tend to be true at the same time.
The real story is that MongoDB doesn't enforce a schema at the database level by default, but your application absolutely has one. It lives in your code, your query patterns, your indexes, your validation logic, and your API responses. The question isn't whether you have a schema. You do. It's whether you've been honest about it.
A flexible schema isn't an absent schema. It's a schema that's evolvable on purpose. And once you accept that, the actually interesting decisions start: what shape should a document take, what gets embedded, what gets referenced, and how do you keep yourself from rebuilding the whole collection in eight months when the product grows.
Let's break it down.
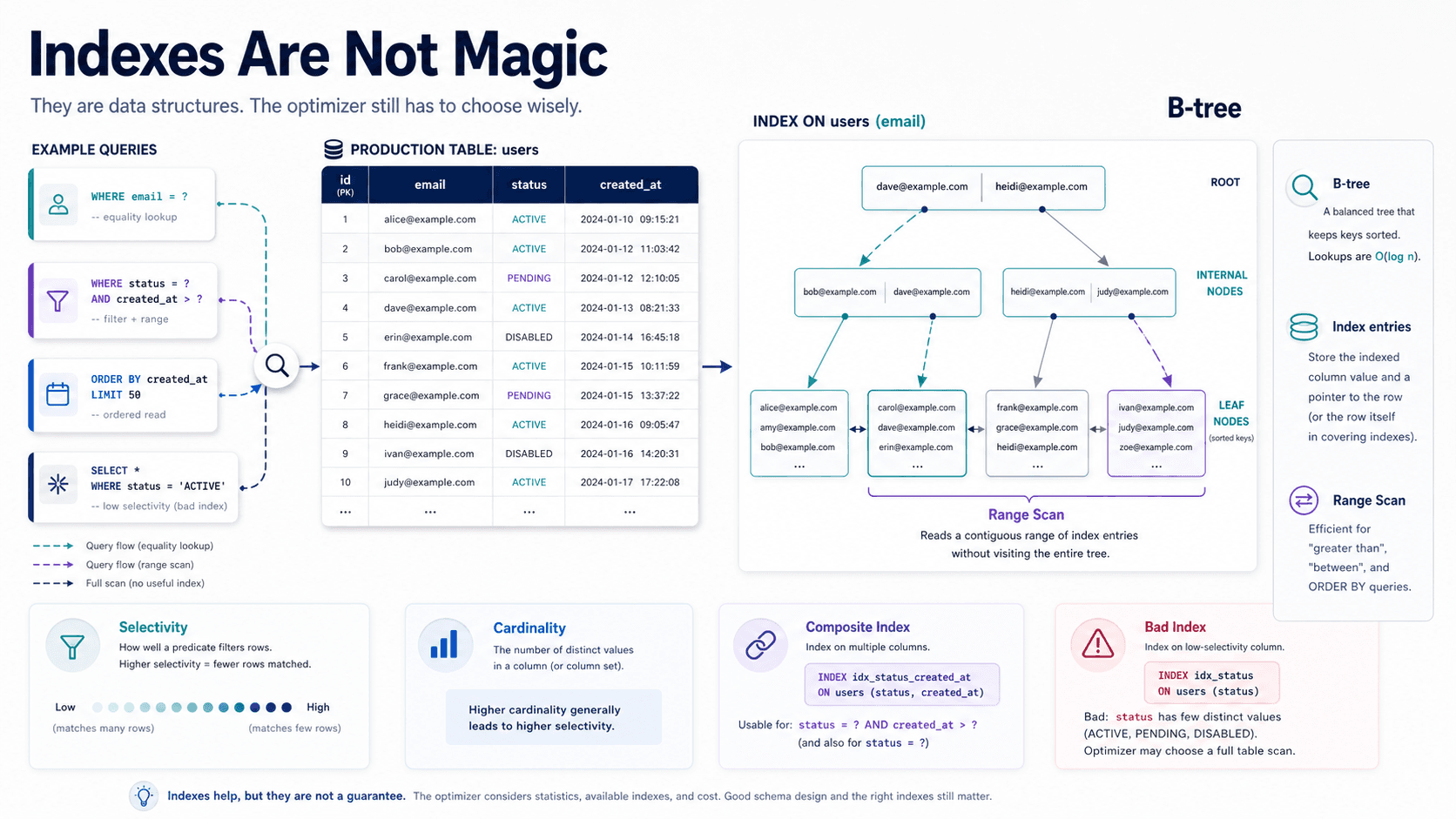
A document is not a row
A row in a relational database is flat. Columns, types, constraints, foreign keys to other tables. You join your way to the bigger picture.
A MongoDB document is something else: a single JSON-shaped tree (BSON under the hood, but you can read it as JSON). It can hold nested objects, arrays of objects, arrays of strings, mixed types, anything you'd put in a JSON file, more or less. The unit you save and retrieve in one call is the whole tree.
// One document — a user with embedded profile and roles
{
_id: ObjectId("64f0a..."),
email: "ada@example.com",
profile: {
displayName: "Ada Lovelace",
timezone: "Europe/London",
locale: "en-GB"
},
roles: ["admin", "billing"],
createdAt: ISODate("2026-04-12T10:14:00Z")
}Notice what just happened. In a relational schema, profile would probably be its own table joined on user_id. Roles would be a junction table. Pulling all of this for one user requires three queries or a join with two JOIN clauses.
In MongoDB, that's one read. And that's the whole pitch: model the data the way your application is going to use it, not the way Codd's normal forms suggest you should.
But, and this is the part people skip, that one document still has rules. It has fields your code expects to exist. It has types you'll silently break if you save a number where you used to save a string. It has a hard size limit (16 MB per document). It has indexes that depend on fields being where you said they'd be.
You're not free of structure. You're just the one responsible for enforcing it.
"Schemaless" is a marketing word, not a design strategy
The flexibility MongoDB offers is real. You can add a new field tomorrow without an ALTER TABLE. You can have documents in the same collection where address.country is a string for old users and an object with code and name for new ones. The database won't stop you.
This is a feature for migrations.
It is not a feature for the steady state.
The steady state should look more like: every document in users has these required fields, these optional fields, this validator, and this index plan. The flexibility is the buffer that lets you change those expectations without downtime, not permission to throw arbitrary JSON in and figure it out later.
The mechanism MongoDB gives you for this is schema validation, expressed as a JSON Schema document on the collection itself:
db.createCollection("users", {
validator: {
$jsonSchema: {
bsonType: "object",
required: ["email", "createdAt"],
properties: {
email: { bsonType: "string", pattern: "^.+@.+$" },
profile: {
bsonType: "object",
properties: {
displayName: { bsonType: "string" },
timezone: { bsonType: "string" }
}
},
roles: {
bsonType: "array",
items: { bsonType: "string" }
}
}
}
},
validationLevel: "moderate"
})validationLevel: "moderate" is the friend of every team that adopts validation late: it enforces the rules on inserts and on updates of already-valid documents, while leaving the legacy weird ones alone until you migrate them deliberately. Use it. The "you can't enforce a schema on existing data" excuse is dated.
If you're using Mongoose, your schema already carries this same intent, plus runtime defaults, casting, and middleware. If you're using the native driver, validators plus a typed model in your code do the job. The point isn't which tool. It's that something somewhere is asserting "documents in this collection look like this."
Embedding: when the child has no life of its own
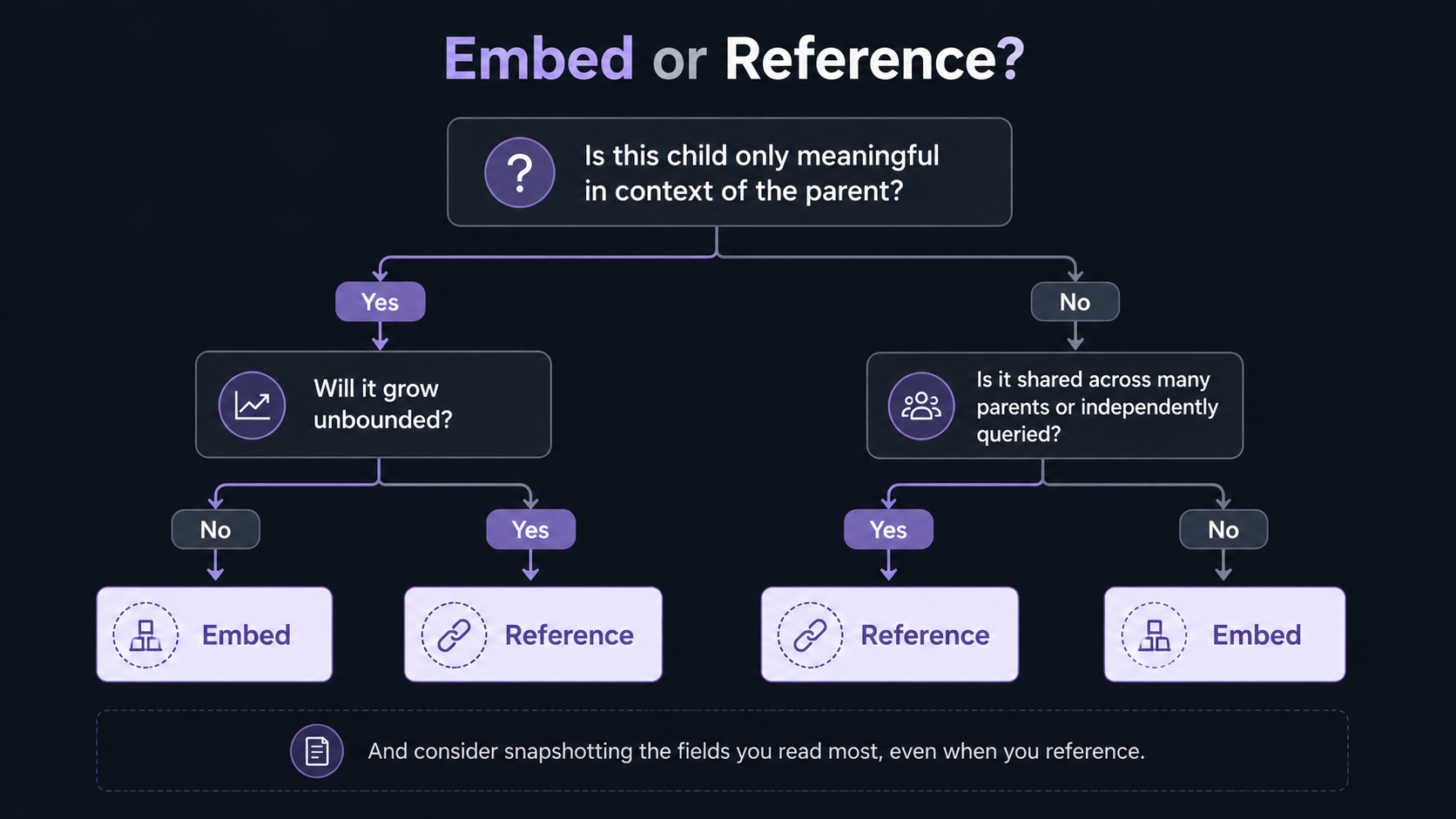
Now the actually fun question. When do you embed and when do you reference?
Start here: embedding is for data that's only meaningful in the context of its parent.
A user's profile preferences. The line items of an order. The comments on a blog post (within reason). The shipping address of this specific delivery. None of those things are objects you'd query on their own. You'd never write "give me all the line items where price > 100" across all orders without grouping them back to their orders. The line items belong to the order. Embed them.
// One document — an order with embedded items
{
_id: ObjectId("..."),
customerId: ObjectId("..."),
status: "paid",
placedAt: ISODate("2026-05-04T08:00:00Z"),
items: [
{ sku: "BK-001", title: "The Pragmatic Programmer", quantity: 1, unitPrice: 32.00 },
{ sku: "MUG-13", title: "404 mug", quantity: 2, unitPrice: 12.50 }
],
totals: { subtotal: 57.00, shipping: 4.99, total: 61.99 }
}What you get out of this:
- One read. Show the order, render its items. No joins, no
$lookup, no second round trip. - Atomicity. A single document write is atomic in MongoDB. You can update the order and its items together without a transaction.
- Locality. All of this lives on disk together. The query that fetches one order touches one place.
What you give up:
- Querying line items independently is awkward. You can do it with
$elemMatchor$unwind, but it's not what the data is shaped for. - The document grows with the array. Twelve items is fine. Twelve thousand is a problem.
- Updating a nested field rewrites the whole document at the storage layer.
The first warning is mostly a non-issue if you've been honest about your access patterns. The second is the one to watch, which is why the embedding heuristic has a sibling rule.
The unbounded array trap
If the embedded array can grow without limit, don't embed it.
Comments on a blog post: probably fine, even popular ones top out at a few hundred. Comments on a viral thread: not fine, you'll hit document size limits and rewrite a multi-megabyte document every time someone replies.
A user's order history: don't embed it. A user has one order this year, three hundred next year, and nobody knows.
A chat room's messages: definitely don't embed. They're a stream, they keep coming forever.
The size limit is 16 MB per document, but the practical limit is much lower. Once you're rewriting megabytes on every small change, you've turned every reply into a giant disk write and every read into a load of stuff the user didn't ask for. Performance drops in the way that's hardest to debug: gradually, from "fine" to "we should look at this someday" to "the on-call is paging."
When the answer is "items grow forever", it's referencing time.
Referencing: when the child has its own life
Referencing is what it sounds like. Instead of nesting the data, you store an _id (or a small subset of fields) that points to another document, often in another collection.
// orders collection — references the customer rather than embedding
{
_id: ObjectId("..."),
customerId: ObjectId("64f0a..."), // points into users collection
status: "paid",
items: [ /* ... */ ],
placedAt: ISODate("2026-05-04T08:00:00Z")
}
// users collection
{
_id: ObjectId("64f0a..."),
email: "ada@example.com",
profile: { /* ... */ }
}To read the order and the customer, you do two queries (one for the order, one for the user), or you use $lookup in an aggregation pipeline:
db.orders.aggregate([
{ $match: { _id: ObjectId("...") } },
{
$lookup: {
from: "users",
localField: "customerId",
foreignField: "_id",
as: "customer"
}
},
{ $unwind: "$customer" }
])$lookup is MongoDB's join. It's a perfectly fine tool. It's slower than reading from one collection, and it doesn't optimise the way a relational planner would, but it's there for the cases where you genuinely need it.
When to reference:
- The referenced data has its own lifecycle: it's created, updated, deleted independently. A user updates their name; you don't want to chase every embedded copy of it across thousands of orders.
- The referenced data is shared by many parents. A product referenced by ten thousand orders shouldn't be embedded ten thousand times, at least not the source-of-truth version.
- The collection of children is unbounded (the trap above).
- You need to query the children directly as first-class objects: "give me all orders shipped to this address last month", "all messages by this user", etc.
The cost of referencing is the extra read or the $lookup. That cost is real, sometimes a lot more than it should be, and it's why the next pattern exists.

The hybrid: snapshot what you read, reference what you change
Real schemas aren't pure embed or pure reference. The interesting ones do both, and the rule is simple once you see it.
Reference for the source of truth. Embed a snapshot for the read path.
Take an order again. The customer changes their address, their email, their display name, all the time. So the customer is a separate document. Easy.
But the order has its own snapshot of who it shipped to and what it cost at the moment it was placed. If you only stored customerId and joined every time, two things break: shipping addresses change (your old order would now claim it shipped to the customer's new address, which is wrong), and prices change (revenue reports built on $lookup would silently drift).
{
_id: ObjectId("..."),
customerId: ObjectId("64f0a..."), // reference — for "who is this customer now?"
// snapshot — what was true at the time of the order
customerSnapshot: {
email: "ada@example.com",
displayName: "Ada Lovelace"
},
shippingAddress: {
line1: "12 Lovelace Lane",
city: "London",
country: "GB"
},
items: [
{ sku: "BK-001", title: "The Pragmatic Programmer", quantity: 1, unitPrice: 32.00 }
]
}That's not a denormalisation sin. That's how an order is supposed to work. It's a record of a transaction, frozen in time. The reference points to the customer, the embedded snapshot answers what did we agree to ship and to whom.
You'll find this same pattern everywhere once you start looking for it. Invoice line items snapshot the product name and price. Audit logs snapshot the actor's email at the moment of the action. Notification rows snapshot the message body so editing the original doesn't rewrite history.
The trick is being intentional about which fields are snapshots and which are references. Don't snapshot what changes meaningfully often and needs to be current. Don't reference what would force you to do a $lookup on every list view.
Design around your queries, not around your nouns
Here's the rule that matters more than any of the above.
In a relational database, you design around the entities (users, orders, products), and let the query planner figure out joins. In MongoDB, you design around the queries.
Before you decide what a User document looks like, ask: what are the three or four screens this collection has to feed?
Maybe it's:
- Login → fetch by email, return profile and roles. Hot path.
- Account settings page → return everything we know about the user.
- Admin user list → email, name, signup date, plan tier. That's it.
- "User has unread notifications" badge → just a count.
Now the schema basically writes itself. Login wants email indexed. Settings wants the whole document, fine, embed the obvious sub-objects. Admin list wants a few fields, those need to be cheap to read, so they're top-level, not buried six levels deep. The unread count is the only thing that lives at high frequency, so you might keep it on the user document as a denormalised counter and update it via $inc instead of recounting from the notifications collection on every page load.
// users collection, designed for the four queries above
{
_id: ObjectId("..."),
email: "ada@example.com", // unique-indexed, login lookup
emailLower: "ada@example.com", // for case-insensitive search if you need it
name: "Ada Lovelace",
signupDate: ISODate("2026-01-04T..."),
plan: "pro",
roles: ["admin"],
unreadNotifications: 3, // denormalised counter, $inc'd on write
profile: {
timezone: "Europe/London",
locale: "en-GB",
bio: "Mathematician, programmer, etc."
}
}Compare this to the version a relational reflex would produce (users table, user_profiles table, user_roles join table, user_settings table), and you can already feel the difference. None of those tables would do anything useful on their own; you'd join them every time. In MongoDB, that join is your schema, baked in.
The corollary: if you find yourself writing $lookup on the hot path of your most common query, the schema is fighting you. Either embed what should be embedded, or denormalise a snapshot, or both.
Common traps that look harmless until they aren't
A few patterns to keep in your peripheral vision.
The everything-document. You decide to embed a user's orders, their messages, their notifications, and their friends list inside the user document because "reads are fast." Six months later the document is multiple megabytes, MongoDB is rewriting all of it on every login, and you're staring at the 16 MB ceiling with a flashlight. Embed bounded children, not unbounded ones.
The deeply nested swamp. Documents nested five levels deep, like user.profile.preferences.notifications.email.frequency. Updating a leaf field requires a $set with a path string that's a typo away from silent failure, indexes on those nested fields are awkward, and the schema becomes a maze. Two levels of nesting is comfortable. Three is sometimes fine. Five is a smell.
Premature referencing. Treating MongoDB like Postgres-with-JSON, normalising everything, and $lookup-ing every read. You've got the worst of both worlds: relational complexity without the relational query planner. If you're going to fight the database, use the right one.
Forgetting the index. The "embed and you only need one read" pitch falls apart if that one read scans the whole collection. An embedded sub-document doesn't change the fact that you still need an index on the field you're filtering by. Every query path you care about should land on an index, full stop.
No schema migration story. Because MongoDB lets you have inconsistent documents, teams sometimes act like they don't have to migrate. Then a year in, half the documents have address as a string, half as an object, the parsing code is a haunted house, and nobody remembers which is which. Use validators. Have a rolling backfill plan when you change a field's shape. Treat a missing migration story as tech debt, not as flexibility.
Flexibility is a tool, not a personality
The thing that makes a MongoDB schema good or bad isn't whether you embed or reference. It's whether you've thought about what the documents actually represent and how they're going to be read.
A document is a unit. Pick units that match the way your application thinks. Embed when the inside truly belongs to the outside. Reference when the inside has its own life. Snapshot the parts of a reference that you'd otherwise be re-fetching all day. Index everything you filter on. Validate everything you save.
And when somebody on the team says "MongoDB is schemaless", smile, nod, then go look at the validator on your users collection. The schema is right there. It's just yours to write, and yours to keep honest.