
One generic AI assistant can be useful. It can explain code, write a small function, suggest a test, or summarize a pull request.
But real software development is rarely one task.
A production feature usually touches architecture, implementation, testing, security, documentation, deployment, and review. That is a lot of mental context. When one assistant tries to do all of it at once, the output often becomes shallow. It may write code before understanding the design. It may generate tests that only confirm the happy path. It may forget security. It may update documentation with confident but incomplete details.
This is where multi-agent development workflows become interesting.
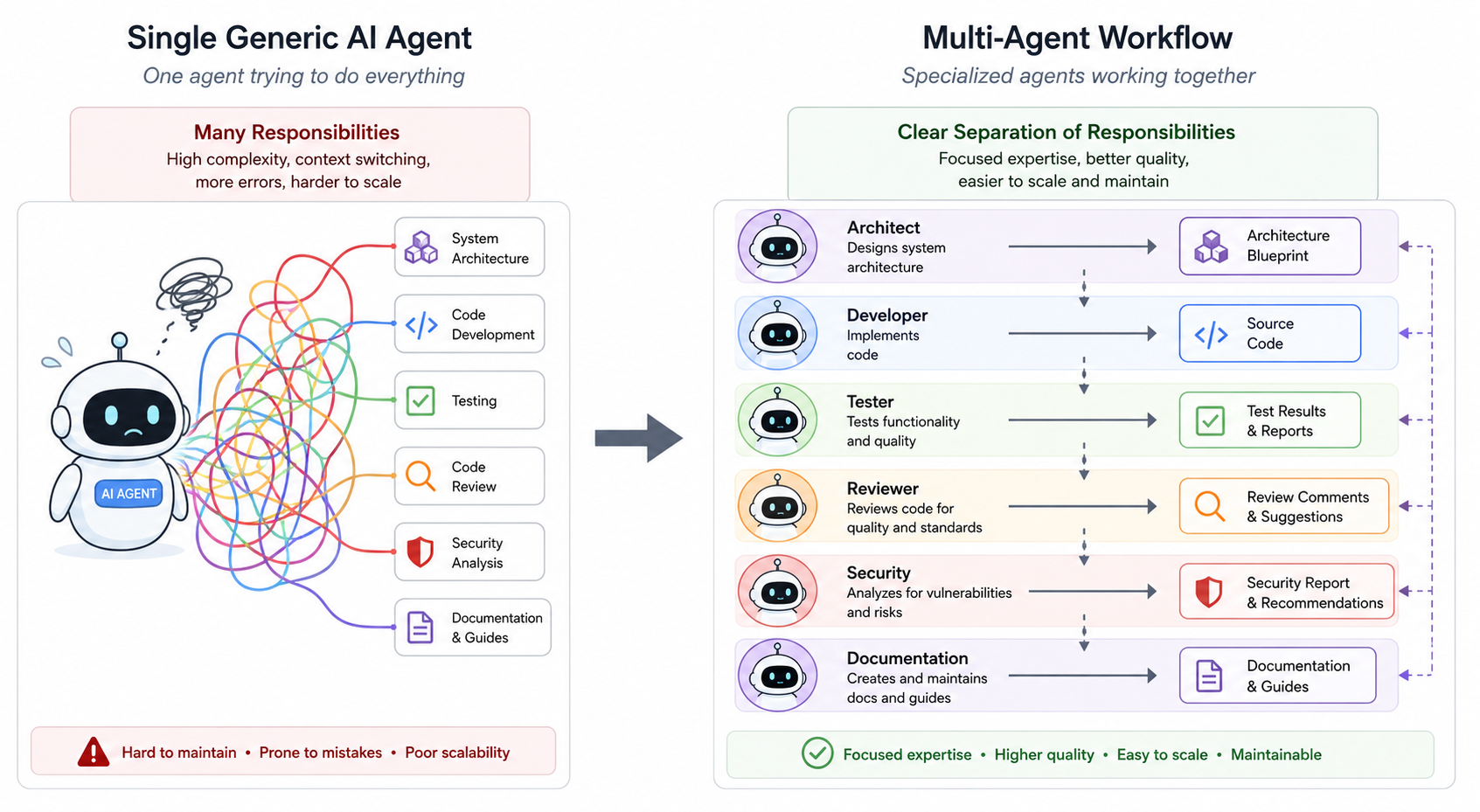
The idea is not "let AI replace the team." That is the wrong mental model. A better model is this: split the work into specialized responsibilities, give each agent a narrow job, and let an orchestrator coordinate the flow.
In other words, treat AI agents more like a small technical review pipeline than like one magical developer.
Why specialized agents work better than one generic agent
A senior engineer does not review a system in one flat pass. They change lenses.
First, they may ask: "Does this design make sense?"
Then: "Is this implementation readable?"
Then: "What can break in production?"
Then: "Are the tests meaningful?"
Then: "Does this need a migration note, runbook update, or API contract change?"
Each lens has different success criteria. A security review is not the same as a documentation review. A test review is not the same as an architecture review. A performance review is not the same as a product behavior review.
A single generic prompt often blends these concerns together. A specialized agent can focus.
For example:
- The Architect Agent checks boundaries, data flow, contracts, and long-term maintainability.
- The Developer Agent makes the concrete code change.
- The Tester Agent creates or improves tests based on behavior.
- The Reviewer Agent checks readability, duplication, naming, and edge cases.
- The Security Agent looks for unsafe input handling, authorization gaps, injection risks, secret leaks, and dangerous dependencies.
- The Documentation Agent updates README files, API docs, changelogs, or internal docs.
- The Orchestrator Agent decides which agents run, in what order, and what context each one receives.
This separation matters because agents are highly sensitive to context. Give an agent too much context, and it may focus on the wrong thing. Give it a narrow role, and the result is usually easier to evaluate.
The orchestrator is the workflow, not the boss
The orchestrator is the most important part of the system.
It should not blindly ask every agent to do everything. That creates noise, cost, and slow feedback. A good orchestrator decides what is needed based on the task.
A small copy change may only need a reviewer.
A database migration may need architect, developer, tester, security, and documentation agents.
A payment-related change may require extra checks around idempotency, logging, fraud signals, and failure recovery.
The orchestrator can follow simple deterministic rules before it calls any model:
type AgentName =
| 'architect'
| 'developer'
| 'tester'
| 'reviewer'
| 'security'
| 'documentation';
type TaskContext = {
title: string;
description: string;
changedFiles: string[];
labels: string[];
};
function selectAgents(task: TaskContext): AgentName[] {
const agents = new Set<AgentName>();
agents.add('reviewer');
if (task.changedFiles.some(file => file.includes('migrations/'))) {
agents.add('architect');
agents.add('tester');
agents.add('documentation');
}
if (task.changedFiles.some(file => file.includes('auth') || file.includes('billing'))) {
agents.add('security');
agents.add('tester');
}
if (task.labels.includes('new-feature')) {
agents.add('architect');
agents.add('documentation');
}
return [...agents];
}This is important: orchestration should not be only "AI decides everything."
Use normal software rules when the decision is obvious. Use AI when the decision needs interpretation.
For example, file paths, labels, test results, and CI failures are deterministic inputs. You do not need an LLM to know that a change in payments/ deserves extra review. A simple rule is cheaper, faster, and more reliable.
Designing the Architect Agent
The Architect Agent should review the shape of the solution before code gets too deep.
Its job is not to write every class. Its job is to ask senior-level design questions:
Does this feature belong in this service?
Are we mixing domain logic with transport logic?
Will this create a hidden dependency between modules?
Is the database model aligned with the behavior?
What happens when this grows 10x?
A useful Architect Agent prompt is specific:
You are an Architect Agent for a backend engineering team.
Review the task and proposed implementation plan.
Focus only on architecture, boundaries, data flow, contracts, and long-term maintainability.
Do not rewrite code unless needed to explain a design issue.
Return:
1. Architecture summary
2. Main risks
3. Suggested design changes
4. Questions for the human developer
5. Decision: approve, approve with changes, or blockNotice what the prompt does not say. It does not ask the agent to "make it better." That is too vague. It tells the agent exactly what lens to use.
The output should be structured because structured output is easier to evaluate and compare between runs.
Designing the Developer Agent
The Developer Agent is the one most teams think about first. But it should not be the first agent in every workflow.
If the task is ambiguous, let the Architect Agent clarify the plan first. If the task is small and well-scoped, the Developer Agent can start directly.
The Developer Agent needs constraints:
You are a Developer Agent.
Implement the requested change with the smallest safe diff.
Follow existing project style.
Do not introduce new dependencies unless clearly justified.
Do not change public behavior outside the requested scope.
Add comments only when they explain non-obvious business rules.
Before editing, summarize:
- files you expect to touch
- behavior you expect to change
- tests you expect to add or updateThat "before editing" step is powerful. It creates a checkpoint. The agent must reveal its intent before it starts changing code.
In an automated workflow, you can store that plan as an artifact:
{
"agent": "developer",
"task_id": "PAY-1842",
"expected_files": [
"src/Billing/PaymentRetryService.php",
"tests/Feature/Billing/PaymentRetryServiceTest.php"
],
"expected_behavior_change": "Retry failed card payments only when the gateway error is recoverable.",
"expected_tests": [
"recoverable gateway error is retried",
"hard decline is not retried",
"retry count is capped"
]
}Later, the Reviewer Agent can compare the actual diff against this plan.
That is how you turn AI work from "mysterious generated output" into an auditable workflow.
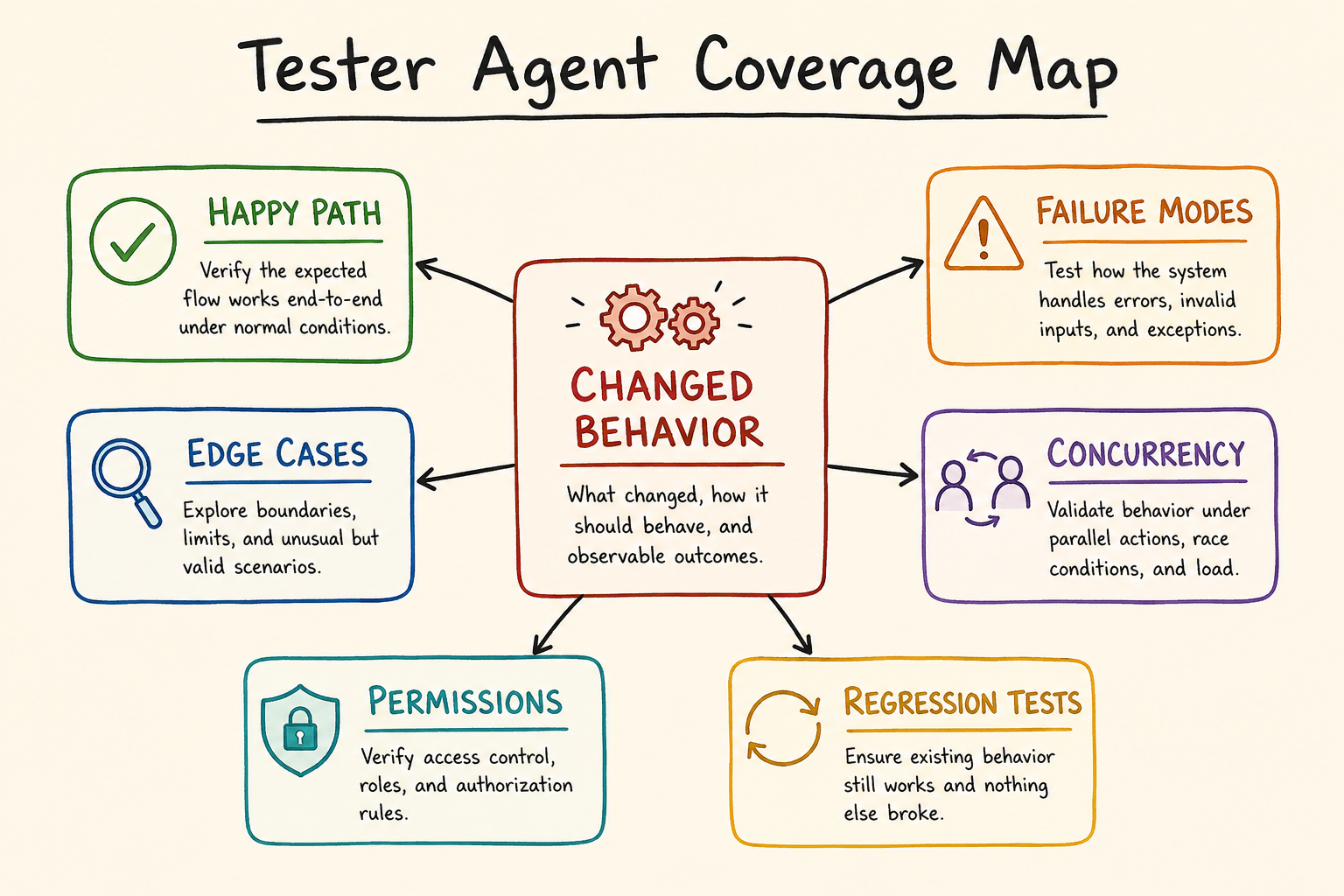
Designing the Tester Agent
A Tester Agent should not only ask, "Are there tests?"
That is too weak.
It should ask:
What behavior changed?
Which edge cases matter?
What can fail because of time, retries, permissions, concurrency, or bad input?
Are tests checking meaningful outcomes or just implementation details?
Here is a practical Tester Agent prompt:
You are a Tester Agent.
Review the task, changed behavior, and diff.
Your job is to identify missing or weak tests.
Focus on behavior, edge cases, failure modes, and regression risk.
Return:
- Existing tests that are relevant
- Missing test cases
- Weak assertions
- Suggested test names
- Highest-risk behavior without coverageFor example, suppose the Developer Agent changes payment retry behavior:
final class PaymentRetryService
{
public function shouldRetry(GatewayError $error, int $attempts): bool
{
if ($attempts >= 3) {
return false;
}
return in_array($error->code(), [
'temporary_unavailable',
'network_timeout',
'processor_busy',
], true);
}
}A weak test only checks one happy path:
public function test_it_retries_temporary_errors(): void
{
$service = new PaymentRetryService();
$this->assertTrue(
$service->shouldRetry(new GatewayError('network_timeout'), 1)
);
}A stronger test suite checks boundaries and negative cases:
public function test_it_does_not_retry_after_the_max_attempt_count(): void
{
$service = new PaymentRetryService();
$this->assertFalse(
$service->shouldRetry(new GatewayError('network_timeout'), 3)
);
}
public function test_it_does_not_retry_hard_declines(): void
{
$service = new PaymentRetryService();
$this->assertFalse(
$service->shouldRetry(new GatewayError('card_declined'), 1)
);
}
public function test_it_retries_only_recoverable_gateway_errors(): void
{
$service = new PaymentRetryService();
$recoverableErrors = [
'temporary_unavailable',
'network_timeout',
'processor_busy',
];
foreach ($recoverableErrors as $code) {
$this->assertTrue(
$service->shouldRetry(new GatewayError($code), 1),
"Expected {$code} to be recoverable."
);
}
}The Tester Agent should help humans find this difference.
Designing the Reviewer Agent
The Reviewer Agent is not the same as the Tester Agent.
The Reviewer Agent cares about code quality.
It should check naming, duplication, unnecessary complexity, hidden side effects, inconsistent project style, and confusing control flow.
A good Reviewer Agent should be strict but not noisy. It should not comment on every personal preference. It should rank issues by impact.
You are a Reviewer Agent.
Review the diff like a senior engineer.
Focus on correctness, readability, maintainability, and unnecessary complexity.
Do not nitpick style unless it reduces clarity or breaks project conventions.
For each issue, include:
- severity: blocker, major, minor, suggestion
- file and line if available
- why it matters
- suggested fixSeverity matters because AI reviewers can easily become too verbose. A pull request with 40 minor comments is not helpful. It creates review fatigue.
The best reviewer output is short, direct, and actionable.
Designing the Security Agent
The Security Agent should have a different mindset.
It should assume the code may be called with malicious input, invalid permissions, leaked secrets, unsafe redirects, dangerous file uploads, or unexpected payloads.
It should check common application risks:
- broken authorization
- SQL injection
- command injection
- unsafe deserialization
- secret exposure
- SSRF
- path traversal
- weak validation
- unsafe logging of sensitive data
- dependency risk
For example, a generic reviewer may accept this code because it works:
$userId = $_GET['user_id'];
$sql = "SELECT * FROM users WHERE id = {$userId}";
$result = $pdo->query($sql);A Security Agent should immediately flag it.
A safer version uses parameter binding:
$userId = filter_input(INPUT_GET, 'user_id', FILTER_VALIDATE_INT);
if ($userId === false || $userId === null) {
throw new InvalidArgumentException('Invalid user id.');
}
$stmt = $pdo->prepare('SELECT * FROM users WHERE id = :id');
$stmt->execute(['id' => $userId]);
$user = $stmt->fetch();The agent should also understand context. Not every risk is equal. A SQL injection risk in an admin-only internal script is still serious, but a public endpoint is more urgent.
Security review should produce a risk summary, not just a list of scary terms.
Designing the Documentation Agent
Documentation is often the first thing skipped when teams move fast.
AI can help, but only if the Documentation Agent is grounded in the actual diff. It should not invent features. It should not write marketing copy. It should explain what changed, how to use it, and what operators or developers need to know.
A useful Documentation Agent prompt:
You are a Documentation Agent.
Update documentation based only on the task, diff, tests, and final behavior.
Do not invent features or configuration options.
If something is unclear, mark it as a question for the human reviewer.
Check whether the change needs updates to:
- README
- API docs
- changelog
- migration guide
- runbook
- troubleshooting guideThe strongest documentation agents are boring in a good way. They are precise. They do not overpromise.
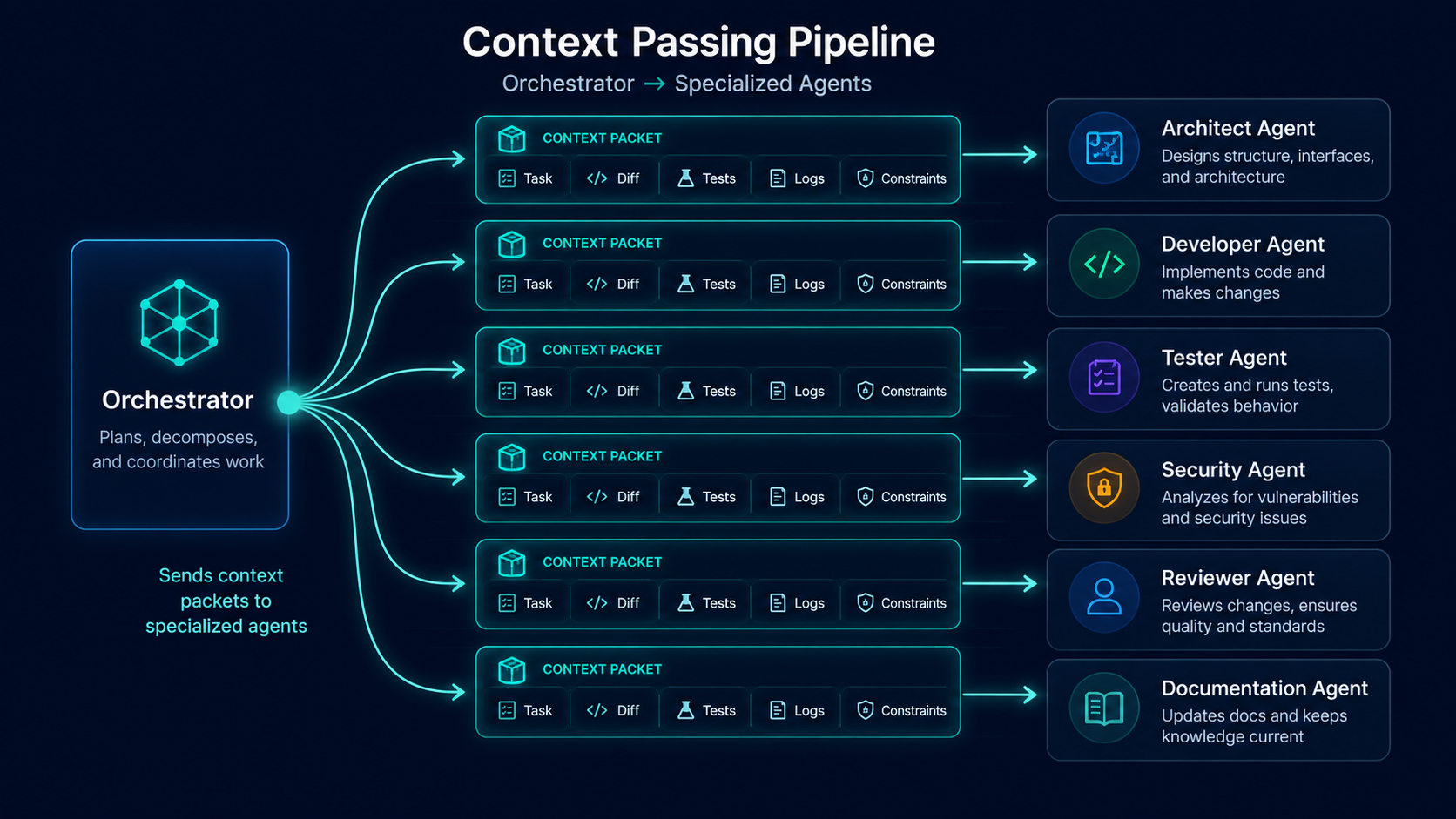
Passing context between agents
A multi-agent workflow can fail if every agent gets the entire repository and a vague instruction.
Context should be curated.
The Architect Agent may need task requirements, high-level code structure, related interfaces, and previous decisions.
The Developer Agent needs the selected files, tests, project conventions, and the architecture decision.
The Tester Agent needs the diff, changed behavior, and test commands.
The Security Agent needs the diff, route definitions, permission model, dependency changes, and data flow.
The Documentation Agent needs the final diff, public behavior, configuration changes, and migration notes.
A simple context package can look like this:
{
"task": {
"id": "AUTH-219",
"title": "Add session timeout for inactive users",
"description": "Users should be logged out after 30 minutes of inactivity."
},
"constraints": [
"Do not change remember-me behavior",
"Must work for API and web sessions",
"Existing tests must continue passing"
],
"changed_files": [
"app/Http/Middleware/TrackUserActivity.php",
"config/session.php",
"tests/Feature/Auth/SessionTimeoutTest.php"
],
"commands": {
"test": "php artisan test --filter=SessionTimeoutTest",
"static_analysis": "vendor/bin/phpstan analyse"
}
}This is not fancy. That is the point.
Good AI engineering often looks like normal software engineering: clear inputs, clear outputs, repeatable steps, and logs.
Guardrails: where deterministic automation beats AI
A multi-agent workflow should not trust AI for everything.
Use deterministic checks wherever possible:
name: ai-assisted-review
on:
pull_request:
types: [opened, synchronize]
jobs:
safety-checks:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install dependencies
run: composer install --no-interaction --prefer-dist
- name: Run tests
run: php artisan test
- name: Run static analysis
run: vendor/bin/phpstan analyse
- name: Check for secrets
run: gitleaks detect --source . --no-gitAI should explain these results, not replace them.
If tests fail, the agent can summarize the failure. But the source of truth is the test runner.
If static analysis fails, the agent can suggest a fix. But the source of truth is the static analysis tool.
If a secret scanner fails, the agent should not decide "it is probably fine." The workflow should block.
That is the healthy relationship: deterministic tools enforce hard rules; AI helps with interpretation, prioritization, and patch suggestions.
A practical multi-agent workflow
Here is one realistic flow:
- A developer assigns a Jira or GitHub issue to the AI workflow.
- The Orchestrator reads the ticket, repository instructions, and changed files.
- The Architect Agent creates a small implementation plan.
- A human approves or adjusts the plan for risky tasks.
- The Developer Agent creates a branch and makes a small diff.
- Tests and static analysis run.
- The Tester Agent checks whether coverage matches the behavior.
- The Security Agent reviews risky files and data flow.
- The Reviewer Agent reviews maintainability.
- The Documentation Agent updates docs if needed.
- The Orchestrator prepares a pull request summary.
- A human reviews and merges.
You can automate some of this. But the human review should remain the final authority, especially for production systems.
What to log
If you build multi-agent workflows, logging is not optional.
You need to know:
- which agents ran
- what input context they received
- what tools they called
- what files they changed
- how many tokens they used
- which tests ran
- what failed
- what the human accepted or rejected
Without this, you cannot improve the workflow. You cannot debug bad outputs. You cannot measure whether agents are helping or creating review debt.
A minimal event log can be simple:
{
"workflow_id": "wf_2026_05_03_001",
"task_id": "AUTH-219",
"agent": "security",
"event": "review_completed",
"duration_ms": 18420,
"input_files": [
"app/Http/Middleware/TrackUserActivity.php",
"routes/web.php"
],
"findings": 2,
"blockers": 0,
"token_usage": {
"input": 12400,
"output": 1800
}
}This becomes your workflow memory.
Common mistakes
The first mistake is running too many agents on every task.
That feels advanced, but it creates noise. Start with two or three agents: Reviewer, Tester, and Security. Add Architect and Documentation when needed.
The second mistake is letting agents edit the same files without coordination.
That creates messy diffs and conflicting changes. Prefer a sequence: plan, implement, test, review, document.
The third mistake is hiding AI output from humans.
A reviewer should see what the AI changed, why it changed it, what tests ran, and what risks were found.
The fourth mistake is treating AI review as approval.
AI can help find issues. It does not own production responsibility. Your team does.
A small starting point
You do not need a complex platform to start.
Start with this:
- One prompt for PR summary.
- One prompt for test review.
- One prompt for security review.
- One CI workflow that runs tests and static analysis.
- One Markdown report attached to the pull request.
Then measure:
Did review time decrease?
Did missed tests decrease?
Did production bugs decrease?
Did developers trust the output?
If not, improve the workflow before adding more agents.
Final thoughts
Multi-agent development is not about creating a digital team of fake engineers.
It is about building a better engineering workflow.
The best version looks boring from the outside: clear roles, small diffs, test results, security checks, review summaries, documentation updates, and human approval.
That is exactly why it can work.
Specialized agents are useful because they reduce cognitive overload. They let each review step focus on one job. The orchestrator turns those steps into a repeatable process.
The future of AI-assisted development will not be one giant prompt that says "build the feature."
It will be a system of small, reliable workflows where agents help engineers think, verify, and ship safer software.
Further reading
- OpenAI Agents SDK: tracing and agent workflows: https://openai.github.io/openai-agents-python/tracing/
- OpenAI Agents SDK: tools: https://openai.github.io/openai-agents-python/tools/
- OpenTelemetry documentation: https://opentelemetry.io/docs/





