So you added a search box.
Two days later it's the slowest part of your application. The table has a couple million rows, the box accepts free text, and somewhere in the controller a teammate wrote WHERE description LIKE '%' . $term . '%' because that's the obvious thing to do when someone asks "make this searchable."
It works. For a while.
Then a marketing campaign brings traffic. Then the table grows. Then the query that ran in 40ms on a developer laptop runs in 4 seconds on production, and your database CPU graph starts looking like a heart monitor in an action movie.
Welcome to the moment every backend engineer has, eventually: the moment you find out that LIKE and "search" are not the same word.
Let's break down what's actually happening, why MySQL's full-text search exists, where each one wins, and where each one falls on its face.
What LIKE Actually Does
LIKE is a string-matching operator. It compares one string against a pattern with two wildcards: % for any sequence of characters, _ for exactly one character. That's it. There is no language model, no relevance ranking, no understanding of words. It's substring matching with two metacharacters bolted on.
SELECT id, title
FROM articles
WHERE title LIKE 'mysql%';This query is fast. The % is at the end, so MySQL can use a B-tree index on title and do a range scan over the rows starting with mysql. The optimiser sees a left-anchored prefix and treats it like title >= 'mysql' AND title < 'mysza'. Index scan. Cheap.
Now flip it:
SELECT id, title
FROM articles
WHERE title LIKE '%mysql%';The leading % makes the index useless. There's no prefix to anchor on. MySQL has to read every row, materialise the title column, and run a substring check against each one. That's a full table scan dressed up as a query. On a million rows it's slow. On ten million it's a meeting with your DBA.
The third shape is the worst:
SELECT id, title, body
FROM articles
WHERE body LIKE '%performance tuning%';Now you're scanning every row and reading a long TEXT column off disk for each one and doing a substring search inside that text. There's no shortcut. The optimiser has nothing to work with. You get linear time in the row count multiplied by the average length of body.
This is the part most tutorials skip: LIKE doesn't search for words. It searches for character sequences. To it, '%cat%' happily matches category, educate, and vacation along with the actual mentions of cats. There is no concept of word boundaries. There is no concept of relevance. There is no ranking. Every row that matches the pattern is equal in the eyes of the operator, returned in whatever order the storage engine felt like producing them.
For tiny tables and exact prefix searches, that's fine. For anything resembling a search experience, it's wrong on three axes at once: it's slow, it's noisy, and it can't tell you which result is the best one.
Enter Full-Text Search
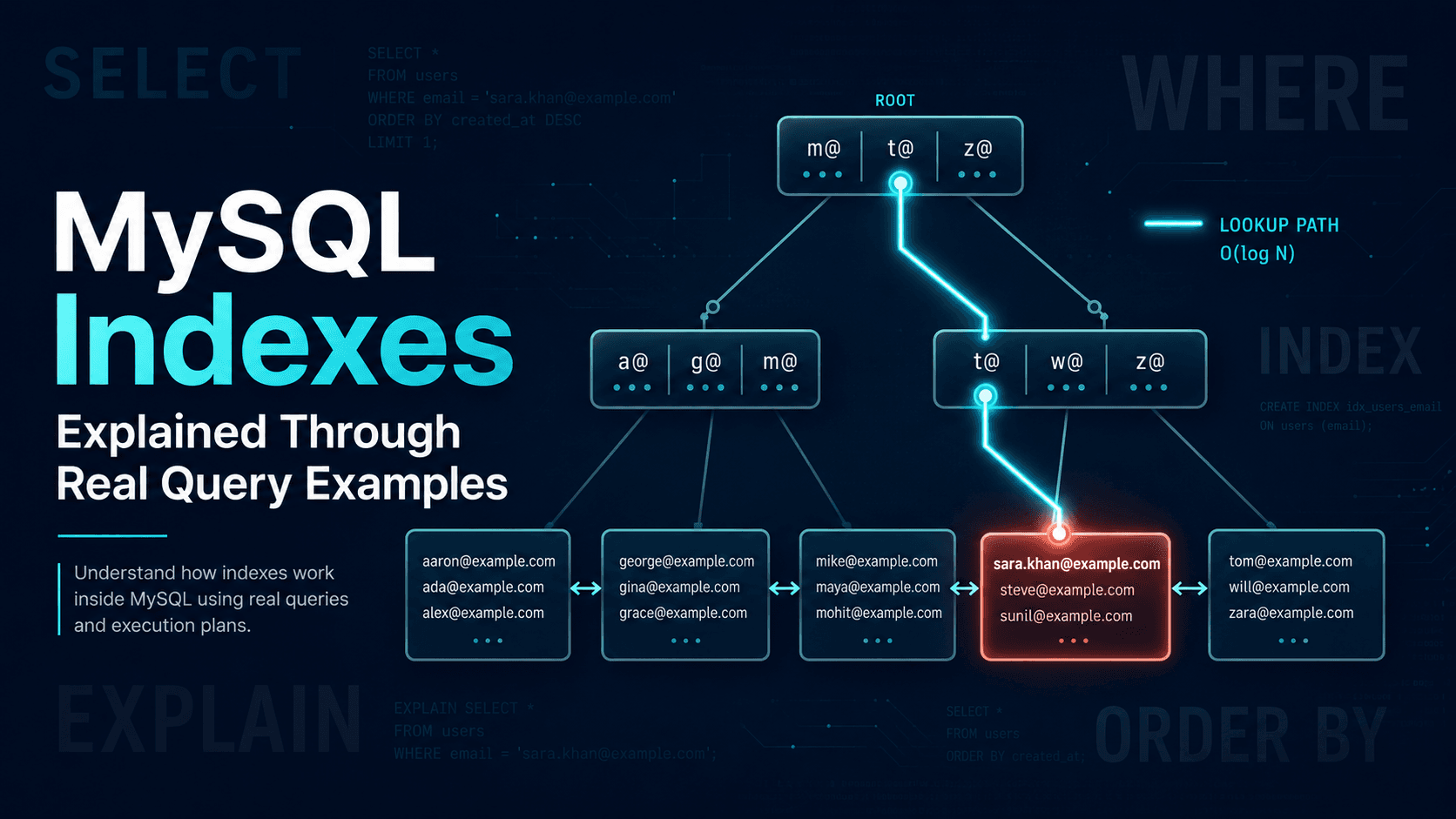
FULLTEXT is a different kind of index, with a different kind of query operator on top.
When you add a FULLTEXT index on a column, MySQL doesn't store another B-tree of the column's values. It builds an inverted index: a structure that maps individual words back to the rows that contain them.
CREATE TABLE articles (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(255),
body TEXT,
FULLTEXT KEY ft_articles (title, body)
) ENGINE=InnoDB;You can also add it later:
ALTER TABLE articles ADD FULLTEXT KEY ft_articles (title, body);That index now contains a token list. Words like performance, tuning, mysql, index each point to the set of rows where they appear, plus a position so MySQL can score how relevant each row is to a multi-word query.
You query it with MATCH ... AGAINST:
SELECT id, title
FROM articles
WHERE MATCH(title, body) AGAINST('performance tuning');This is not a substring search. MySQL tokenises the query string into words, looks each one up in the inverted index, intersects the row sets, and computes a relevance score per row. You get back rows that contain those words, ordered by how relevant they look. Most relevant first, when you select MATCH(...) AGAINST(...) as a column or order by it.
SELECT
id,
title,
MATCH(title, body) AGAINST('performance tuning') AS score
FROM articles
WHERE MATCH(title, body) AGAINST('performance tuning')
ORDER BY score DESC
LIMIT 20;The columns inside MATCH(...) must exactly match a FULLTEXT index. You can't MATCH(title) against an index defined on (title, body) and you can't MATCH(title, body, author) against an index on (title, body). The index is the contract.
There's also a small but useful fact most people miss: since MySQL 5.6, FULLTEXT is supported on InnoDB tables. Before that it was MyISAM-only, and a generation of articles online still tells you to switch your engine to MyISAM "because that's the only way." That advice is a decade out of date. If you're on a modern MySQL, you almost certainly want to keep your tables in InnoDB and add FULLTEXT indexes there.
Three Modes That Behave Differently
AGAINST has a second argument that controls how it interprets the query. You'll mostly use two of them.
Natural language mode is the default. It treats the query as a chunk of text written by a human, splits it into words, ignores stopwords, and ranks rows using a TF-IDF-style algorithm.
SELECT id, title
FROM articles
WHERE MATCH(title, body) AGAINST('how do I tune mysql performance' IN NATURAL LANGUAGE MODE);Common words like how, do, i get dropped. The remaining tokens (tune, mysql, performance) drive the search. Rows that contain all three score higher than rows with two. Rows where the words are rare in the corpus score higher than rows where they're common. It's a reasonable default for a search box that takes raw user text.
Boolean mode treats the query as a tiny query language, with operators that let you require, exclude, prefix-match, and group terms.
SELECT id, title
FROM articles
WHERE MATCH(title, body) AGAINST('+mysql +performance -mongodb' IN BOOLEAN MODE);The operators that matter:
+word: must contain this word.-word: must not contain this word.word*: prefix match (rows containingperform,performance,performant, etc.)."exact phrase": words must appear in this order.>word/<word: increase or decrease the word's contribution to the score.(grouped terms): combine sub-expressions.~word: penalise rows containing this word, but still include them.
Boolean mode doesn't auto-sort by relevance the way natural-language mode does. Scores are still computed using the same TF-IDF / BM25 ranking, you just have to ORDER BY them yourself if you want ranked results:
SELECT
id,
title,
MATCH(title, body) AGAINST('+mysql +performance' IN BOOLEAN MODE) AS score
FROM articles
WHERE MATCH(title, body) AGAINST('+mysql +performance' IN BOOLEAN MODE)
ORDER BY score DESC;The third mode is with query expansion, which runs the query, finds the top results, pulls keywords out of them, and runs the query again with those keywords added. It can broaden a result set in useful ways, but it also tends to drag in results that have nothing to do with what the user typed. Most production search code skips it.

The Stopword And Minimum-Word-Length Cliffs
This is the part that bites most people the first time they ship a FULLTEXT index.
MySQL doesn't index every word. By default, with the InnoDB full-text engine, there are two filters happening at index time:
- Minimum token length. Controlled by
innodb_ft_min_token_size, default 3. Words shorter than that don't get indexed at all. The MyISAM equivalent isft_min_word_len, default 4, which is why some legacy tutorials warn about a four-letter cliff. That was MyISAM's problem. - Stopwords. Controlled by
innodb_ft_default_stopword, a built-in list of common English words likethe,and,a,is,on,to. Tokens in this list don't get indexed.
Add those two filters together and you get surprising behaviour. Search for to be or not to be, and after stopwords get dropped your effective query is empty. Every word is a stopword. The result set is empty too, even though the phrase is right there in the text.
-- Effective query becomes empty after stopword removal.
SELECT id, title
FROM articles
WHERE MATCH(body) AGAINST('to be or not to be' IN NATURAL LANGUAGE MODE);
-- Returns 0 rows.Search for a programming language called Go, and it doesn't get indexed because it's two letters. Search for SQL keywords, error codes, version numbers (anything short) and the index has nothing to find.
Both filters are configurable. You can lower the minimum token size and you can replace the stopword list with a custom one (or an empty one) by configuring innodb_ft_server_stopword_table or innodb_ft_user_stopword_table. After changing either, you have to rebuild the FULLTEXT index. The reliable way is to drop it and recreate it; on a large table that is not a casual change.
-- innodb_ft_min_token_size is read-only at runtime: set it in my.cnf and
-- restart MySQL before creating any FULLTEXT index you care about.
--
-- [mysqld]
-- innodb_ft_min_token_size = 2
--
-- The stopword table, on the other hand, is dynamic. It's just a table
-- with a single VARCHAR column called `value`:
CREATE TABLE my_stopwords (value VARCHAR(64)) ENGINE=InnoDB;
INSERT INTO my_stopwords (value) VALUES ('lorem'), ('ipsum');
SET GLOBAL innodb_ft_server_stopword_table = 'mydb/my_stopwords';You'll still need to drop and recreate any existing FULLTEXT indexes to pick up the new settings. Plan accordingly. On a large table, that's not a casual change.
There's also the ngram parser for languages that don't separate words with whitespace, like Chinese, Japanese, and Korean. The default tokenizer assumes words are space-delimited; for CJK content you switch the index to WITH PARSER ngram:
CREATE TABLE articles_cjk (
id INT PRIMARY KEY AUTO_INCREMENT,
body TEXT,
FULLTEXT KEY ft_body (body) WITH PARSER ngram
) ENGINE=InnoDB;This indexes overlapping n-grams of length ngram_token_size (default 2). It's not perfect (n-gram search has its own quirks around precision), but it gives you a working full-text experience over languages where LIKE is even worse.
Performance: What Actually Changes
Here's the thing the marketing copy gets right: on a large table, the difference between LIKE '%term%' and MATCH ... AGAINST('term') is night-and-day.
A few mental models for the cost.
LIKE 'foo%' over an indexed column is a B-tree range scan. It reads as many rows as match the prefix. Cost is roughly proportional to the result size, plus a small constant per row to follow the index entry. Fast.
LIKE '%foo%' over the same column is a full table scan. It reads every row, runs a substring check, and discards the ones that don't match. Cost is proportional to the total number of rows, regardless of how few results match. The bigger the table, the worse it gets, and the cost doesn't shrink when the user types a more specific query. A user typing foo and a user typing extremely-specific-product-code-2387 both pay the same scan cost. That's not how search should feel.
MATCH(...) AGAINST('foo') does an index lookup on the inverted index. Cost is roughly proportional to the number of rows containing the word, plus the cost of intersecting and scoring. It scales with the result, not with the table.
In practice, the gap widens fast as the table grows. On a small table (a few thousand rows), LIKE '%foo%' is fine and the overhead of a FULLTEXT index isn't worth it. On a few hundred thousand, you start feeling it. By the time you're past a million rows of text content, LIKE '%...%' queries can take seconds while MATCH ... AGAINST(...) returns in milliseconds for the same dataset.
There's a trade-off on the write side. FULLTEXT indexes are expensive to maintain. Every INSERT, UPDATE to an indexed column, or DELETE has to update the inverted index. Bulk loads into a table with a FULLTEXT index can be much slower than loads into the same table without one, sometimes by an order of magnitude. The standard pattern when bulk-loading is to drop the index, load the data, and recreate the index after. The recreation is itself expensive on a large table, but it's a single bulk build rather than a per-row update storm.
Where Full-Text Falls Short
FULLTEXT is a real win when you're searching natural-language text where word boundaries make sense. It's a worse fit, sometimes a non-fit, when any of these hold.
Substring matches inside a word. Looking for database? Great. Looking for data and wanting to also match database? You need boolean mode with a prefix wildcard (data*), and even that only matches at the start of a word. There's no built-in way to match data inside metadata without going back to LIKE or restructuring your data.
Short words and exact codes. SKUs like AB12, hashtags, version strings like v8, error codes like E11, language names like Go or R. Anything that hits the stopword list or the minimum token length is invisible to the index unless you've reconfigured it. And reconfiguring it widens the index, which costs you on writes and disk.
Fuzzy matching and typos. MATCH ... AGAINST doesn't do fuzzy matching. mysq1 (with a one in place of an l) won't find rows about mysql. accomodation (the common typo) won't find rows about accommodation. There's no built-in stemmer either. run, running, and ran are three different tokens to the engine. Boolean mode's prefix wildcard helps with the simplest cases (run* matches runs, running, runner), but it doesn't help with typos and it doesn't help with irregular word forms.
Numeric and structured data. FULLTEXT is designed for prose. Tokenising numeric IDs, dates, JSON fragments, hex hashes, or URLs gives you a mess. The tokenizer doesn't understand any of that structure. If your "search" is really a structured query disguised as text (invoice numbers, customer IDs, timestamps in arbitrary formats), FULLTEXT is the wrong tool, and a normal indexed column with explicit equality or range conditions is the right one.
Per-row relevance you don't control. The natural-language ranking is a fixed algorithm. You can't easily say "title matches count three times more than body matches" without restructuring your indexes, or running two separate MATCH expressions and adding their scores manually. You can't easily boost recent content. You can't easily mix relevance with business signals like number of views or editorial pinning. This is where most teams eventually outgrow FULLTEXT and move to a real search engine.
The 50% rule (legacy MyISAM only). Worth mentioning because it still confuses people: MyISAM's natural-language MATCH used to drop any term that appeared in more than 50% of the rows, on the theory that such terms weren't selective enough to be useful. This led to the famous "small table, FULLTEXT returns nothing" surprise. InnoDB's FULLTEXT doesn't apply the 50% rule. If you're on InnoDB and seeing zero rows, the cause is almost always stopwords or minimum word length, not the 50% rule.
When LIKE Is Actually The Right Answer
It's fashionable to assume LIKE is always wrong. It isn't.
For left-anchored prefix matching on a small set of columns, LIKE 'foo%' against an indexed column is faster, simpler, and more predictable than building a FULLTEXT index. The classic case is autocomplete on a username, email, or product code:
SELECT id, username
FROM users
WHERE username LIKE 'naz%'
ORDER BY username
LIMIT 10;This is exactly what B-trees were built for. Don't introduce a full-text engine to do it.
For exact substring matches that must include short words and codes, LIKE '%E11%' works and MATCH(...) AGAINST('E11') doesn't (without reconfiguring the index). If your search is closer to "find this string anywhere in this column" than to "find documents about this concept," substring matching is genuinely the right primitive.
For small tables, LIKE '%foo%' over a few thousand rows costs almost nothing. The full-table scan finishes before the planner finished thinking about it. Adding a FULLTEXT index slows down writes for no measurable read benefit at that size.
For structured fields stored as strings (UUIDs, IPs, ISBNs, status codes), you don't want a tokenizer interpreting them. LIKE keeps the data as opaque strings, which is usually what you want for that kind of column.
The mistake isn't using LIKE. The mistake is using LIKE '%...%' on a multi-million-row table with a free-text user-input search box, then being surprised when the database catches fire.
A Real Decision Tree
When someone hands you a "make this searchable" request, walk through it in this order.
Is the column small and the search left-anchored? Use a B-tree index and LIKE 'prefix%'. Done.
Is the search free-form text over real human-language content (titles, descriptions, articles, comments) on a table that's already large or growing fast? Add a FULLTEXT index on the relevant columns and use MATCH ... AGAINST. Pick natural-language or boolean mode based on how clever you want the query language to be. Watch for the stopword and minimum-token cliffs and tune them if your domain hits them.
Do you need typo tolerance, stemming, multi-language analyzers, custom relevance, faceting, geo, autocomplete with relevance, "did you mean," or per-tenant index control? You've outgrown FULLTEXT. Move the search workload to a dedicated engine (Elasticsearch, OpenSearch, Meilisearch, Typesense) and let MySQL stay good at being a database. Treat the search index as a derived store, kept in sync via the application layer or a CDC pipeline. The split sounds heavy, but it's the right split: MySQL is excellent at being the source of truth and bad at being a search engine; specialised engines are the opposite.
Are you searching structured data dressed up as text? Stop. Don't use either LIKE or FULLTEXT. Normalise the data into the columns and indexes you actually need.
The whole point is that LIKE and FULLTEXT aren't competing for the same throne. They're solving different problems that happen to share a SQL keyword family. Once you can name which problem you have, the choice is almost obvious. And the next time someone asks "make this searchable," you'll know which question to ask back before you start typing the query.