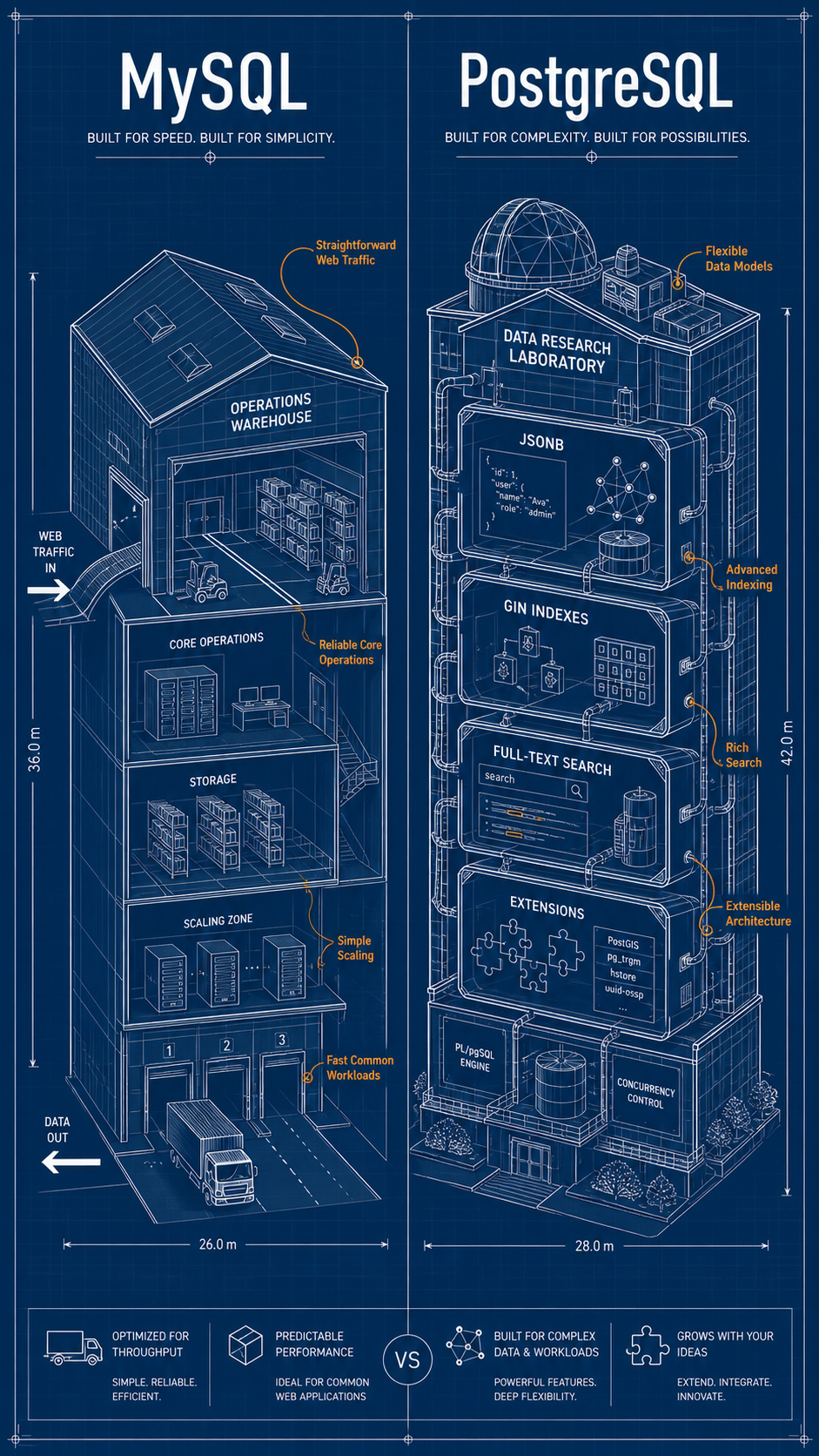
This Is Not A Database Religion Article
You don't need another "PostgreSQL is better" or "MySQL is faster" argument.
Real backend work is messier than that.
You inherit a database. You join a team. You debug a slow query. You design a feature that needs JSON filters, search, reporting, constraints, or heavy writes. Suddenly the database choice is not abstract anymore.
Both MySQL and PostgreSQL can power serious production systems. The practical question is: where do they feel different when you're writing backend code?
JSON: Both Support It, But The Feel Is Different
Both databases support JSON, but PostgreSQL's jsonb often feels more naturally queryable for complex document-style use cases.
PostgreSQL example:
SELECT id, email
FROM users
WHERE preferences->>'theme' = 'dark';You can also index JSONB with GIN indexes for containment-style queries:
CREATE INDEX idx_users_preferences_gin
ON users USING gin (preferences);That can be useful when JSON is not just storage, but part of your query model.
MySQL also supports a native JSON type and JSON functions:
SELECT id, email
FROM users
WHERE JSON_EXTRACT(preferences, '$.theme') = 'dark';In many MySQL apps, teams use generated columns to index specific JSON paths:
ALTER TABLE users
ADD theme VARCHAR(20)
GENERATED ALWAYS AS (JSON_UNQUOTE(JSON_EXTRACT(preferences, '$.theme'))) STORED,
ADD INDEX idx_users_theme (theme);That works well when you know which JSON fields matter.
Practical Takeaway
If your JSON is mostly flexible metadata, either database can work. If your JSON becomes a heavily queried document model, PostgreSQL usually gives you more native indexing options and operators.
But be honest: if you query the same JSON key every day, it may deserve a real column.
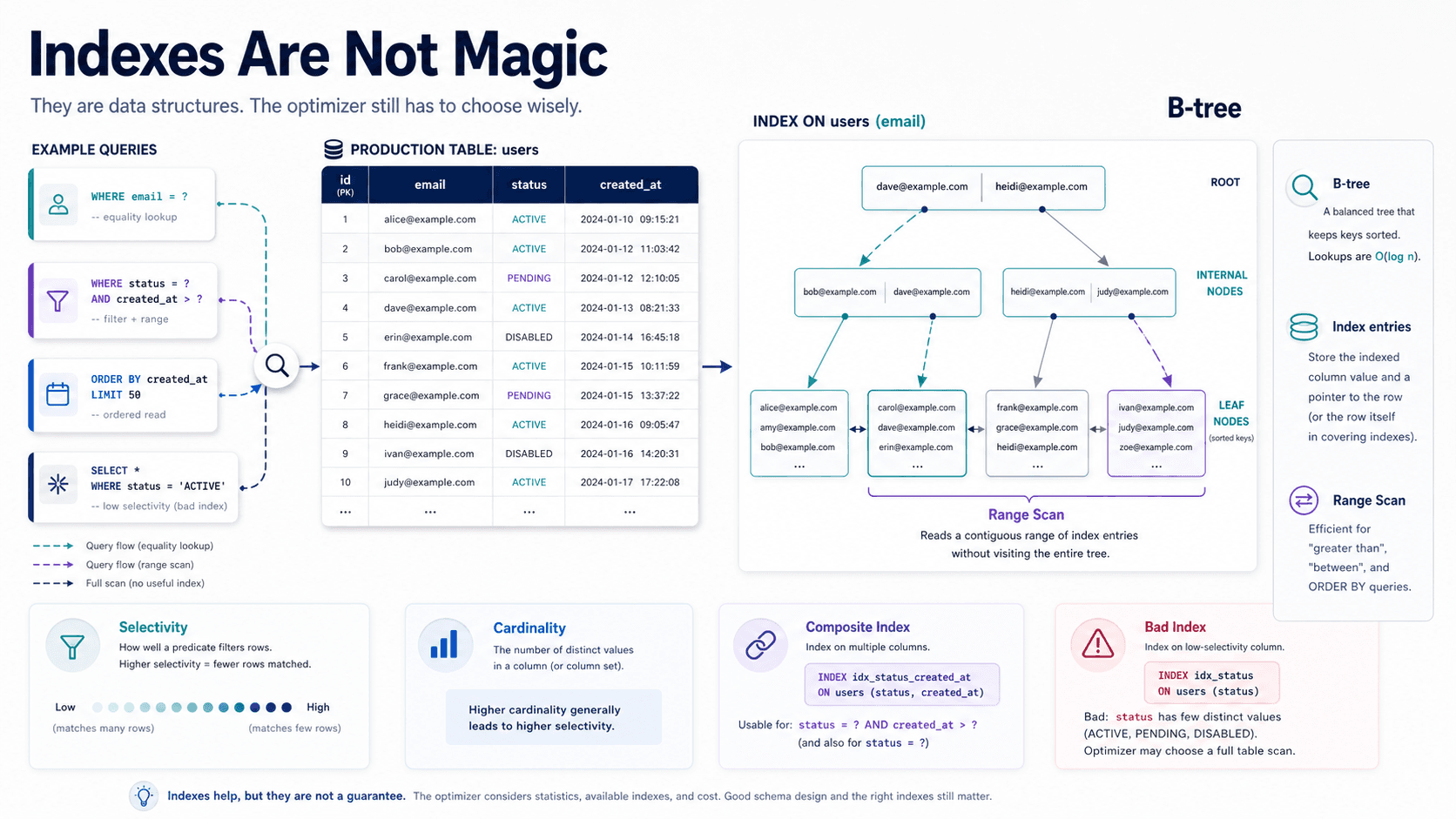
Indexes: PostgreSQL Gives You More Shapes
MySQL's B-tree indexes are excellent for many application queries:
CREATE INDEX idx_orders_user_created
ON orders (user_id, created_at);That helps common queries like "show this user's latest orders."
PostgreSQL supports regular B-tree indexes too, but it also gives you more specialized index types and features: GIN, GiST, BRIN, partial indexes, expression indexes, and more.
A partial index can be very practical:
CREATE INDEX idx_active_subscriptions_user
ON subscriptions (user_id)
WHERE status = 'active';This index only covers active subscriptions. If 90% of your rows are canceled or expired, that can be a big deal.
An expression index can also be useful:
CREATE INDEX idx_users_lower_email
ON users (lower(email));Then your case-insensitive email lookup can use an index.
Practical Takeaway
MySQL indexing is often straightforward and effective. PostgreSQL gives you a larger toolbox when your access patterns become specialized.
That toolbox is powerful, but it also gives you more ways to over-engineer. A fancy index nobody understands is not a win.
Full-Text Search: Built-In vs Search Engine
Both MySQL and PostgreSQL support full-text search.
MySQL:
SELECT id, title
FROM articles
WHERE MATCH(title, body) AGAINST ('database indexing');PostgreSQL:
SELECT id, title
FROM articles
WHERE to_tsvector('english', title || ' ' || body)
@@ plainto_tsquery('english', 'database indexing');PostgreSQL full-text search is very flexible. MySQL full-text search can be simpler to start with.
But for product search with typo tolerance, synonyms, ranking tuning, faceting, autocomplete, and analytics, you may eventually want Elasticsearch, OpenSearch, Meilisearch, Typesense, or another dedicated search engine.
The database is a good search tool until search becomes the product.
Concurrency And Locking
PostgreSQL is known for strong MVCC behavior. Readers and writers often coexist nicely because reads do not block writes in common cases.
MySQL with InnoDB also uses MVCC and can handle serious concurrency, but developers must understand gap locks, next-key locks, isolation levels, and how indexes affect locking behavior.
Here's a common backend lesson: your transaction does not just lock "the idea" of a row. It locks according to the query plan.
Bad or missing indexes can make locking behavior much worse.
UPDATE orders
SET status = 'expired'
WHERE status = 'pending'
AND expires_at < NOW();Without a useful index on (status, expires_at), this update may scan and lock far more than you expect.
That's true in both databases in different ways: query design and indexing shape concurrency.
Strictness And Data Correctness
PostgreSQL tends to be stricter by default. It often refuses ambiguous or invalid data instead of quietly converting it.
That strictness can feel annoying during development, but it protects production data.
MySQL has improved a lot over the years, especially with stricter SQL modes, but many older MySQL systems still carry legacy assumptions around implicit conversions, zero dates, loose grouping behavior, or permissive schema choices.
Example of a problem you should avoid anywhere:
SELECT user_id, status, COUNT(*)
FROM orders
GROUP BY user_id;This query mixes grouped and non-grouped columns. Depending on configuration and database behavior, it may fail or return misleading results.
The practical advice is simple: prefer strict modes, explicit constraints, and queries that say exactly what they mean.
Extensions And Ecosystem
PostgreSQL has a strong extension culture. PostGIS is the classic example for geospatial workloads. Other extensions support trigram search, UUID generation, statistics, scheduling, vector search, and more.
MySQL has a huge hosting and operations footprint. It's common in Laravel ecosystems, e-commerce systems, managed hosting platforms, and teams that value operational familiarity.
Choosing a database is not only about features. It's also about your team's operational comfort.
A database nobody on the team can tune is like buying a race car without knowing how to change tires.
Which One Should You Choose?
Choose PostgreSQL when:
- You need advanced indexing. Partial, expression, GIN, GiST, and BRIN indexes can solve real problems.
- You expect complex reporting queries. PostgreSQL often feels excellent for analytical SQL inside the app database.
- You rely on rich data types. JSONB, arrays, ranges, and extensions can be useful.
- You want strict correctness by default. It pushes you toward explicit data modeling.
Choose MySQL when:
- Your team already knows it deeply. Operational familiarity matters.
- Your workload is classic web application CRUD. MySQL handles this very well.
- Your hosting stack is MySQL-first. Managed support can be easier.
- You value simple, predictable patterns. Especially in Laravel-heavy teams.
Final Tips
The best database choice is rarely made by reading feature checklists. It's made by understanding your product's read patterns, write patterns, team skills, and failure modes.
I've worked on systems where MySQL was absolutely the right choice because the team knew it inside out. I've also seen PostgreSQL save a design because partial indexes and JSONB made an ugly workaround unnecessary.
Don't choose a database to win an argument. Choose the one your team can operate confidently when production is loud.
Good luck choosing boring infrastructure that keeps working 👊