Have you ever built a simple RAG demo, uploaded a few docs, asked a question, and felt like the future had arrived?
Then you added real company documents, old PDFs, permissions, stale wiki pages, duplicated content, and users asking weird questions. Suddenly the future started returning confident nonsense with citations to the wrong paragraph.
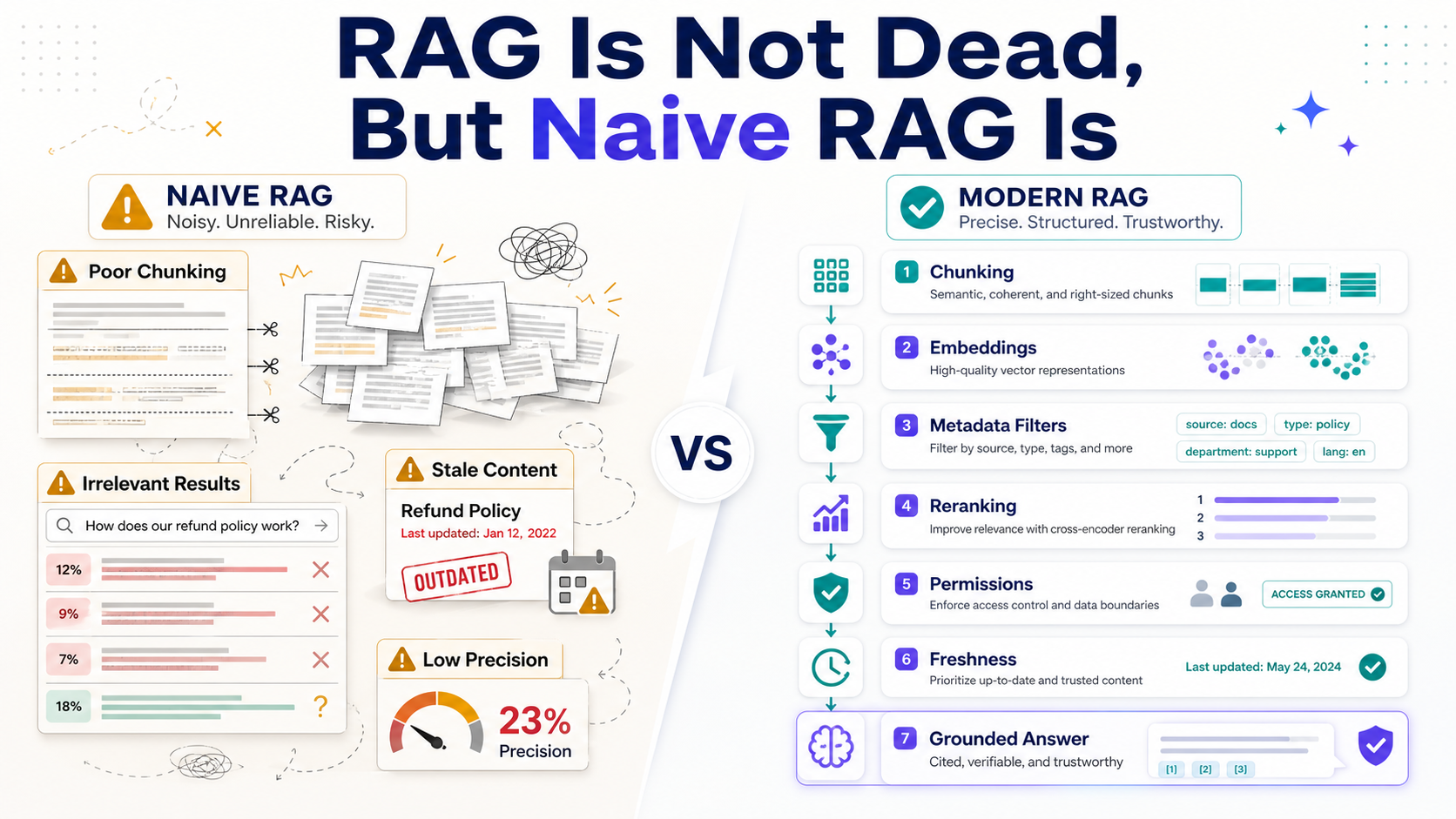
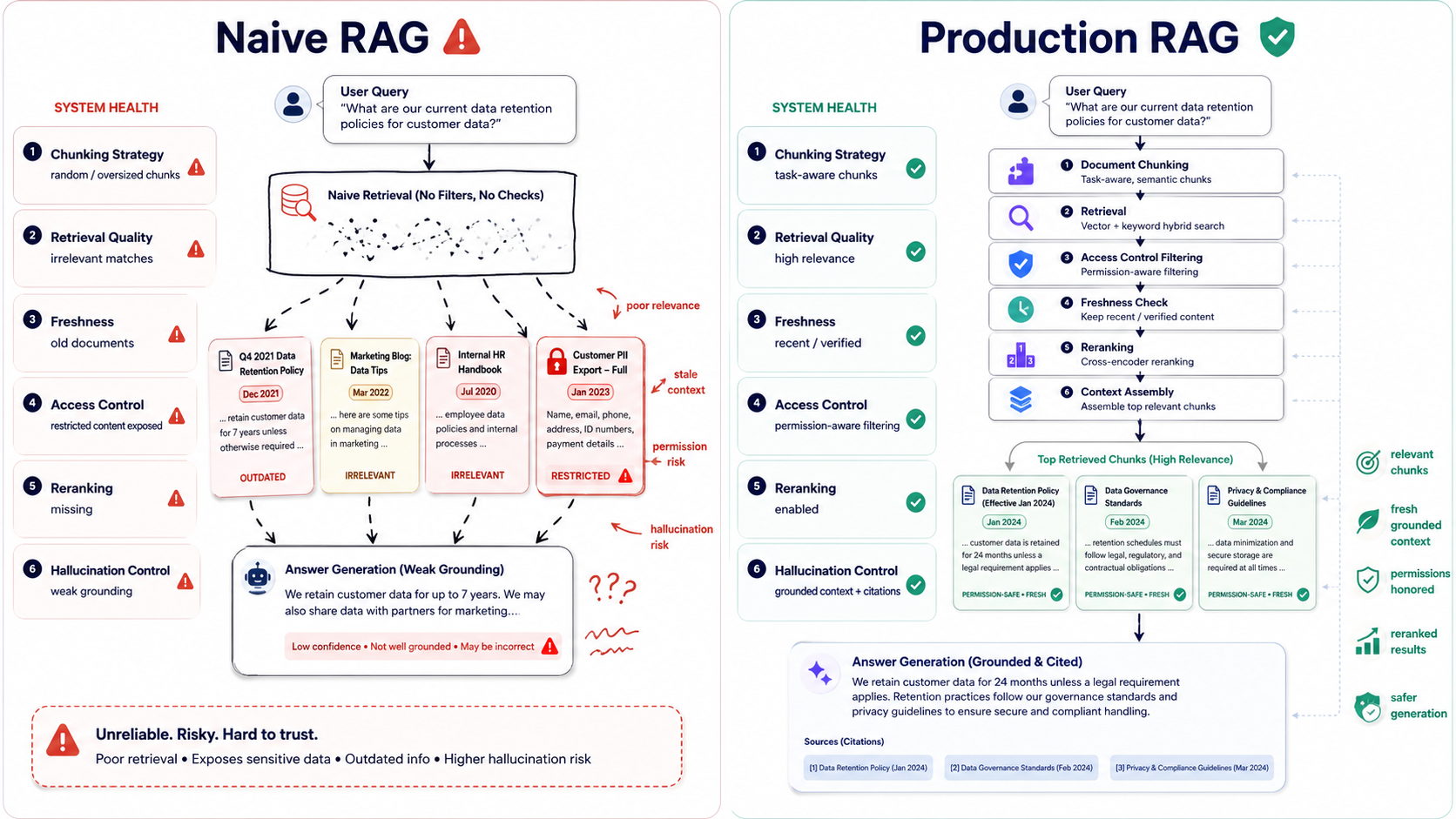
That's the difference between demo RAG and production RAG. Retrieval-Augmented Generation is not dead. Naive RAG is.
The Naive RAG Pattern
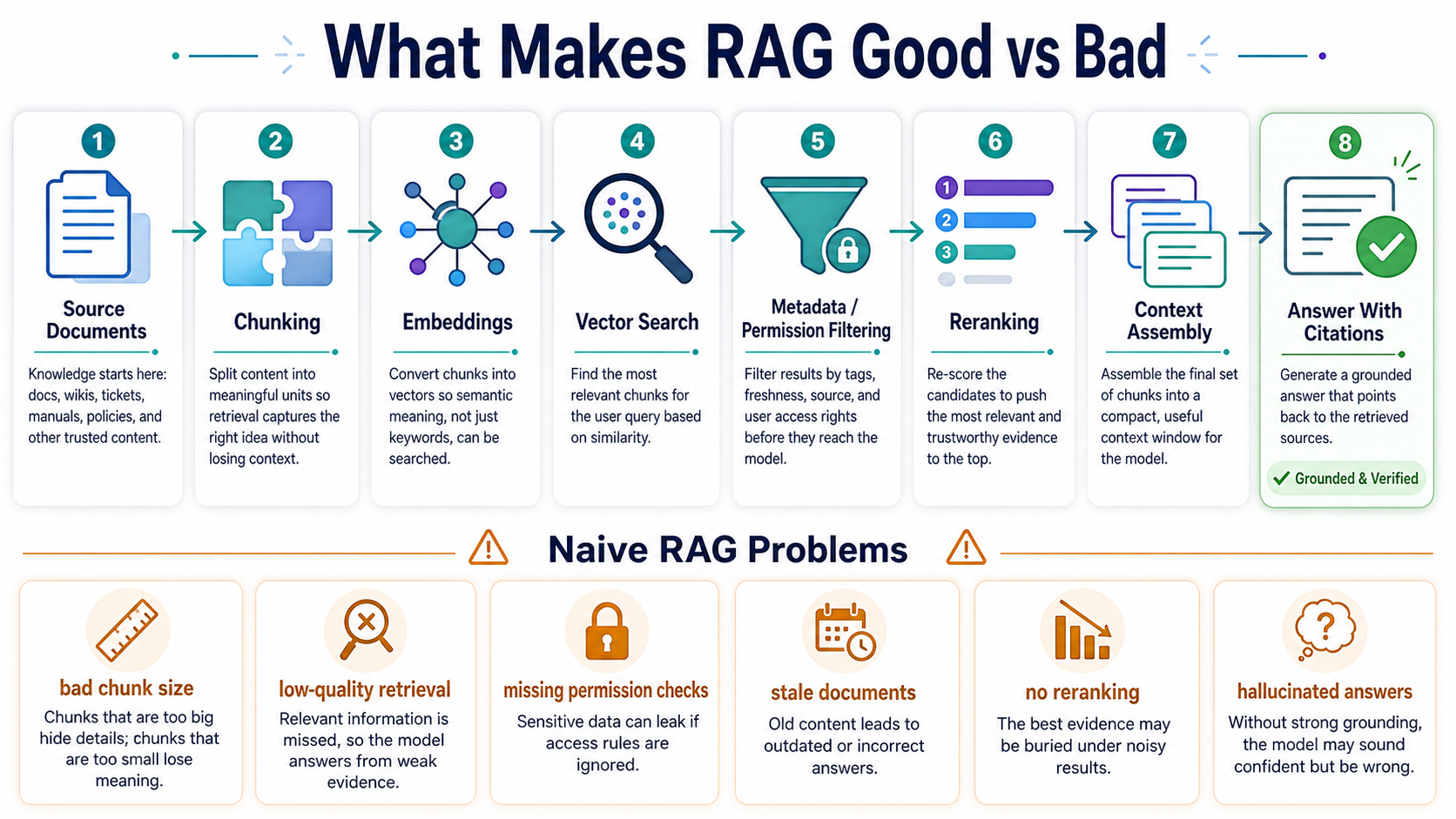
Naive RAG usually looks like this: split documents into chunks, embed each chunk, store vectors, retrieve the top matches, stuff them into a prompt, and ask the model to answer.
That works surprisingly well for small demos. It's like using a flashlight in a clean garage. But production knowledge bases are not clean garages. They're storage units full of old boxes, mislabeled cables, and one critical document hiding behind a broken chair.
The Basic Flow
- Ingest documents. Load files, web pages, tickets, or database content.
- Chunk text. Break content into smaller pieces.
- Create embeddings. Convert chunks into vectors for similarity search.
- Retrieve context. Find chunks related to the user's query.
- Generate an answer. Ask the model to answer using retrieved context.
Here's a very simplified version:
query = "How do refunds work?"
query_embedding = embed(query)
chunks = vector_store.search(query_embedding, top_k=5)
answer = llm.generate(
prompt=f"Answer using this context:\n{chunks}\n\nQuestion: {query}"
)This is fine as a learning example. The problem is that production failures usually happen before the model answers. The wrong chunks go in, so the wrong answer comes out.
Chunking Is Not Just Splitting Text
Bad chunking quietly ruins RAG.
If chunks are too small, they lose meaning. If they're too large, retrieval becomes noisy. If you split in the middle of a procedure, policy, or code example, the model gets half the recipe and guesses the rest.
Chunking is like cutting a cake. You want slices people can actually eat, not crumbs or the whole cake on one plate.
Better Chunking Questions
- What is the natural unit? A section, function, ticket comment, policy clause, or FAQ answer may be better than raw tokens.
- Do chunks need metadata? Source, date, owner, product area, permission group, and version often matter.
- Should chunks overlap? Some overlap helps preserve meaning across boundaries.
- Can structure be preserved? Headings, tables, code blocks, and lists should not be flattened blindly.
- What should not be indexed? Draft docs, secrets, private data, and outdated content may need exclusion.
A better chunk record might look like this:
{
"text": "Refunds are allowed within 30 days...",
"source": "billing-policy.md",
"section": "Refund Rules",
"updated_at": "2026-03-01",
"owner": "Billing",
"permission_group": "support"
}That metadata is not decoration. It helps filtering, ranking, freshness, permissions, and debugging.
Retrieval Needs More Than Similarity
Vector similarity is useful, but it is not the same as correctness.
A query can be semantically close to an outdated document. A chunk can use similar words but describe a different product. A user may ask a question that needs exact matching, not fuzzy meaning.
Search is like asking a librarian for books. A good librarian doesn't just grab books with similar titles. They check edition, author, shelf, topic, and whether you're allowed to read the archive copy.
Production Retrieval Often Combines
- Vector search. Good for semantic similarity and fuzzy language.
- Keyword search. Good for exact terms, IDs, error codes, and product names.
- Metadata filters. Good for permissions, dates, teams, regions, and versions.
- Reranking. Good for reordering candidates after broader retrieval.
- Query rewriting. Good for expanding vague user questions into searchable terms.
A two-stage retrieval flow might look like this:
candidates = vector_store.search(query, top_k=50, filters={
"permission_group": user.permission_group,
"product": "billing"
})
top_chunks = reranker.rank(query, candidates)[:8]The first stage casts a wider net. The reranker then sorts the best candidates more carefully. That extra step can matter a lot when the knowledge base is large.
Permissions Are Not Optional
One of the biggest RAG mistakes is treating retrieval like a pure search problem.
It's also an access control problem. If a user cannot access a document in the normal product, the RAG system should not reveal it just because the embedding is similar.
This is where naive RAG becomes dangerous. A model doesn't need to "hack" anything if your retriever hands it private context.
Permission Rules
- Filter before generation. The model should never receive unauthorized chunks.
- Store permission metadata. Access control needs to exist at retrieval time.
- Test cross-user leakage. Build tests where one user asks about another user's data.
- Handle citations carefully. A citation can leak document names or private structure.
- Log retrieval decisions. You need to debug why a chunk was selected.
Here's the principle in code form:
filters = {
"tenant_id": user.tenant_id,
"permission_groups": {"$in": user.groups},
"is_published": True
}
chunks = retriever.search(query, filters=filters)The model should not be trusted to ignore unauthorized data. Don't give it that data in the first place.
Freshness And Evaluation Matter
A RAG answer can be grounded and still wrong if it's grounded in stale content.
Freshness matters for pricing, policies, APIs, runbooks, legal language, product behavior, and incident response. If your system retrieves a 2024 document for a 2026 question, the answer may sound great and still be outdated.
Common RAG Problems
- Stale chunks. Old content stays indexed after the source changes.
- Duplicate content. The same answer appears in multiple versions.
- No eval set. Teams rely on vibes instead of known test questions.
- No failure taxonomy. Every bad answer becomes "the model hallucinated," even when retrieval failed.
- Missing citations. Users can't verify where the answer came from.
Evaluation is the part everyone wants to skip. Don't skip it. You need a set of real questions, expected sources, expected answer qualities, and known edge cases.
Final Tips
The best RAG systems I've seen are less about clever prompts and more about disciplined data plumbing. Clean ingestion, good metadata, permission-aware retrieval, reranking, freshness checks, and evals do more than one magical prompt ever will.
My opinion: RAG isn't dead because companies still need models to work with private, changing, domain-specific knowledge. But naive RAG is absolutely not enough for serious systems.
Build the boring retrieval layer well. Your model will look smarter because your system got smarter 👊





