
Pull request summaries look simple. A developer changes code, AI reads the diff, AI writes a summary, reviewers save time. Nice, right?
But a safe pull request summary is not just a nicer version of git diff. A good PR summary should help reviewers understand what changed, what behavior is different, where the risk is, which tests were run, which tests are missing, and whether migrations or operational steps are involved.
A bad PR summary can do the opposite. It can hide risk behind confident language, claim tests were run when they were not, describe intent instead of actual code, miss a dangerous file, and make reviewers trust the pull request too quickly.
So the goal is not "generate a beautiful summary." The goal is "generate a reviewer-friendly, evidence-based summary." That means the assistant must be grounded in the diff, CI results, file metadata, and repository rules.
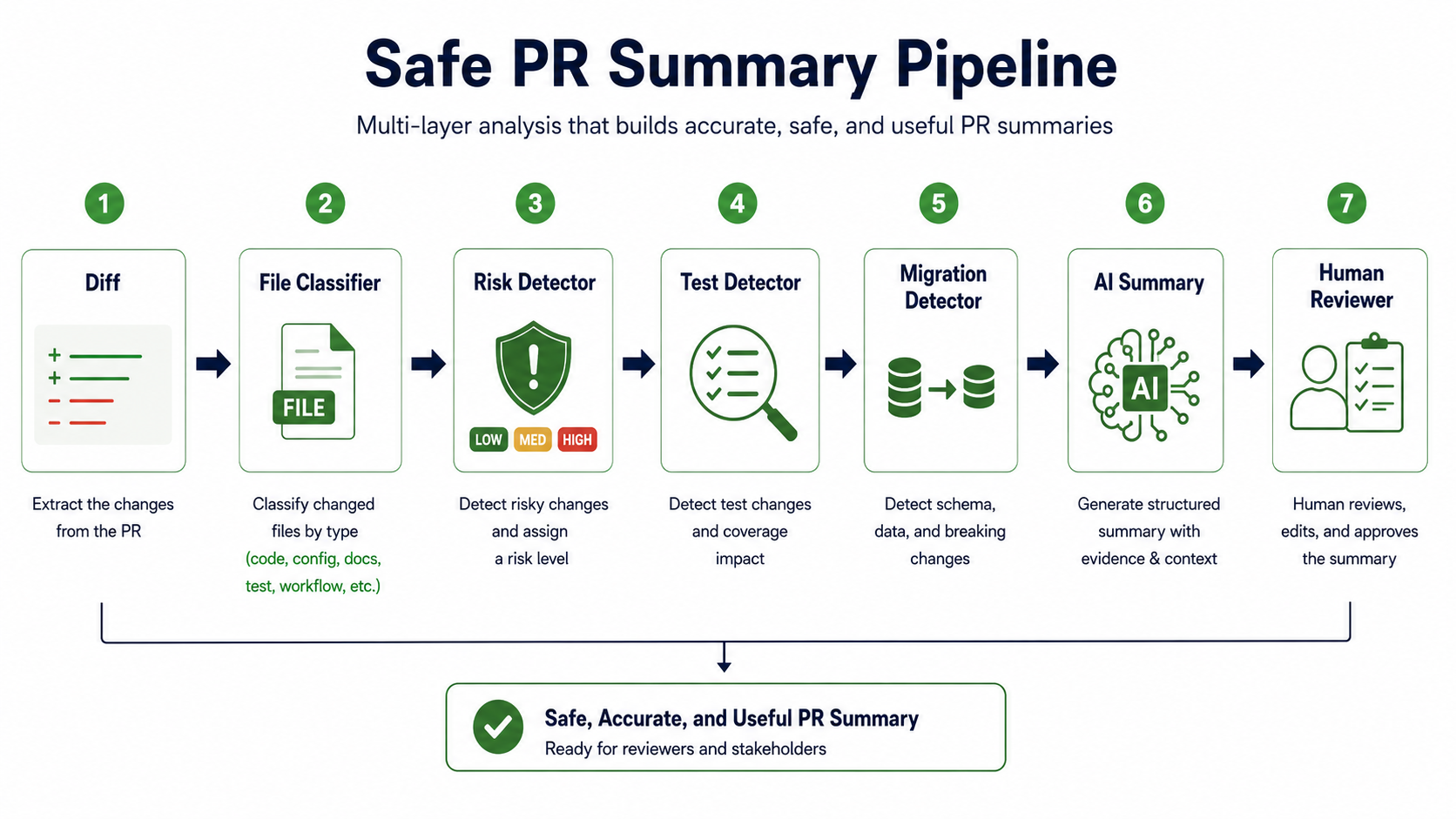
What a safe PR summary must include
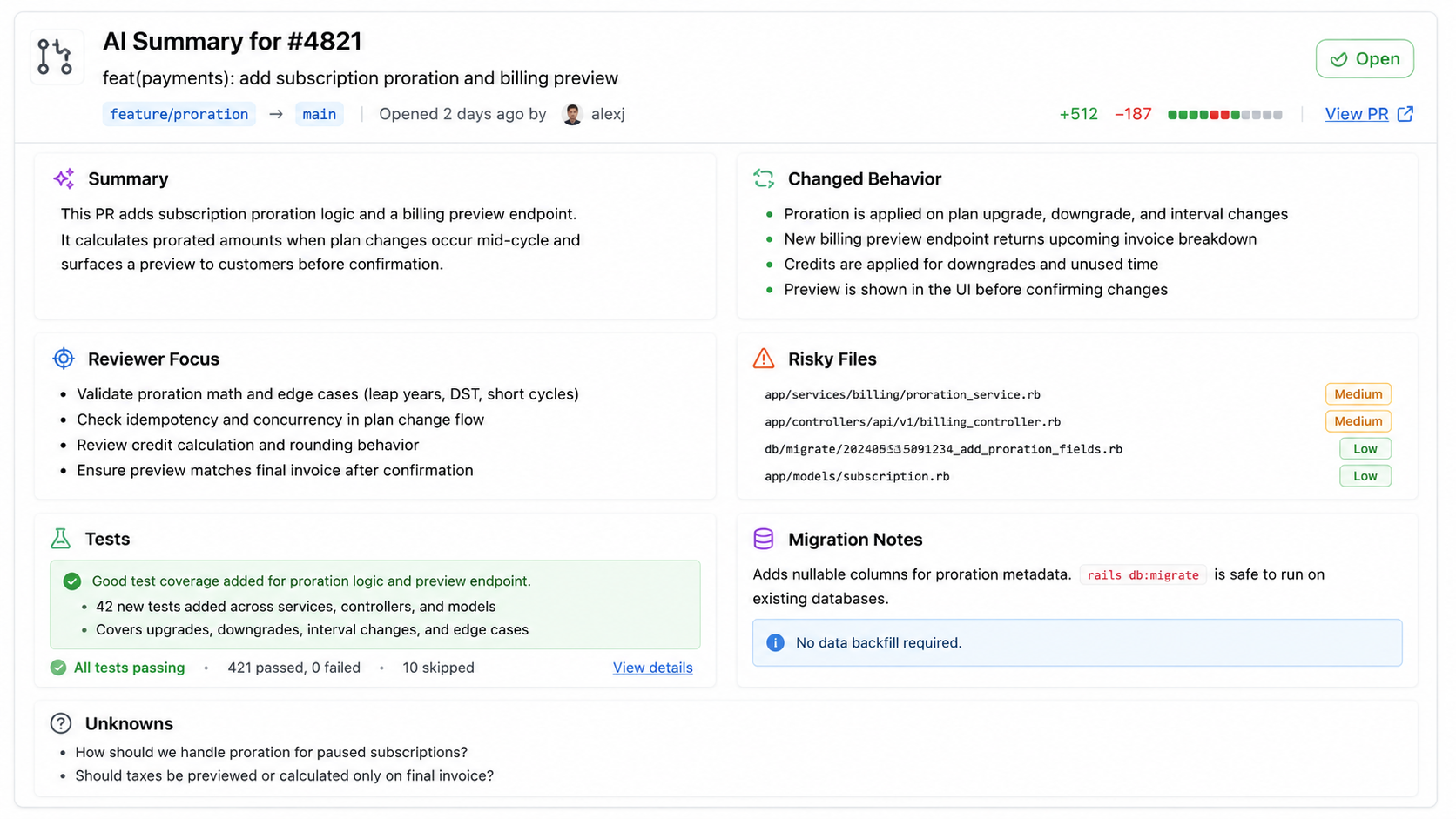
A useful PR summary should answer these questions. What changed and why does it matter? What user-visible or system behavior changed? Which files are risky? Were tests added or updated, which were run, and are there missing tests? Are there database migrations or configuration changes? Does a reviewer need to focus on anything specific?
A weak summary says:
This PR updates the billing logic and improves tests.That is almost useless. A stronger summary says:
This PR changes payment retry behavior so recoverable gateway errors are retried up to 3 times, while hard declines are not retried.
Reviewer focus:
- Confirm the recoverable error list matches gateway documentation.
- Check retry count behavior in PaymentRetryService.
- Review the new tests for hard declines and max attempts.
Tests:
- Added PaymentRetryServiceTest.
- CI reports php artisan test passed.
Risk:
- Billing behavior changed.
- No database migration.This is better because it gives reviewers a map.
Step 1: Read the diff safely
The assistant should not read only the PR title and description. Titles can be wrong, descriptions can be outdated. The diff is the source of truth.
You can collect diff metadata with Git:
git diff --name-status origin/main...HEAD
git diff --stat origin/main...HEAD
git diff --unified=80 origin/main...HEADFor large pull requests, do not blindly send the entire diff to the model. First classify files:
type ChangedFile = {
path: string;
status: 'added' | 'modified' | 'deleted' | 'renamed';
additions: number;
deletions: number;
};
function classifyFile(path: string): string[] {
const tags: string[] = [];
if (path.includes('migrations/')) tags.push('database_migration');
if (path.includes('routes/')) tags.push('route_change');
if (path.includes('auth') || path.includes('permissions')) tags.push('auth');
if (path.includes('billing') || path.includes('payment')) tags.push('billing');
if (path.includes('config/')) tags.push('configuration');
if (path.includes('tests/')) tags.push('test');
if (path.endsWith('.yml') || path.endsWith('.yaml')) tags.push('ci_or_config');
return tags;
}This simple classifier helps the assistant know what deserves attention.
Step 2: Explain changed behavior, not only changed files
Reviewers do not only need a file list. They need behavior. For example:
- if ($attempts > 3) {
+ if ($attempts >= 3) {
return false;
}A file-level summary may say:
Updated retry condition in PaymentRetryService.A behavior-level summary says:
The service now stops retrying at attempt 3 instead of allowing the third retry attempt.That difference matters. Prompt the model to focus on behavior:
You are summarizing a pull request for human reviewers.
Do not only list changed files.
Explain the behavior that changed.
Base your summary only on the diff and provided CI/test data.
If behavior is unclear, say it is unclear.
Do not claim tests were run unless test results are provided.That last line is critical. AI should not invent confidence.
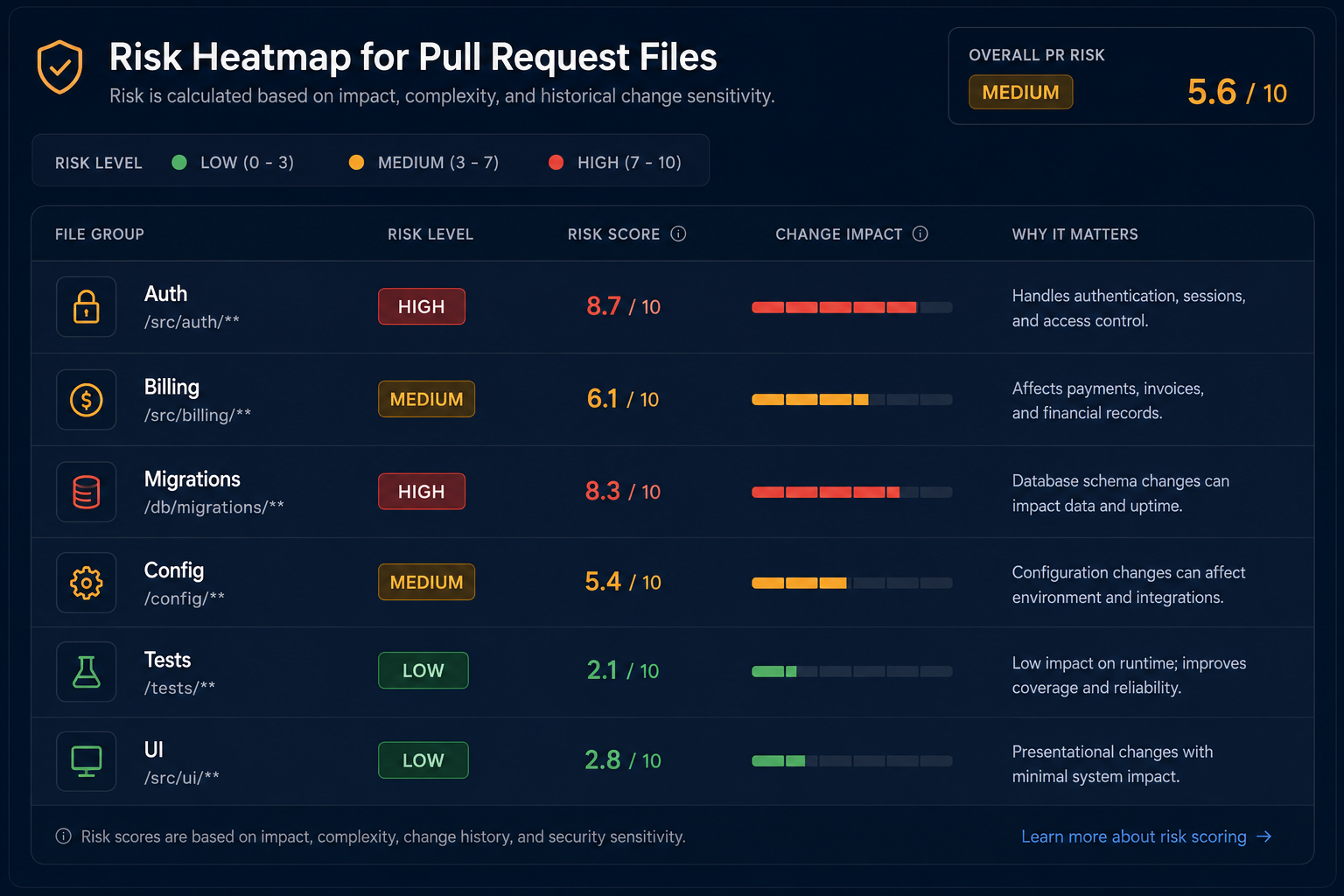
Step 3: Detect risky files before asking AI
Some risk detection should be deterministic. If a PR touches migrations, auth, billing, infrastructure, or dependency lock files, mark it.
type Risk = {
level: 'low' | 'medium' | 'high';
reason: string;
file: string;
};
function detectRisk(file: ChangedFile): Risk[] {
const tags = classifyFile(file.path);
const risks: Risk[] = [];
if (tags.includes('database_migration')) {
risks.push({
level: 'high',
file: file.path,
reason: 'Database migration can affect production data and deployment order.',
});
}
if (tags.includes('auth')) {
risks.push({
level: 'high',
file: file.path,
reason: 'Authentication or authorization behavior changed.',
});
}
if (tags.includes('billing')) {
risks.push({
level: 'high',
file: file.path,
reason: 'Billing or payment behavior changed.',
});
}
if (tags.includes('configuration')) {
risks.push({
level: 'medium',
file: file.path,
reason: 'Configuration change may affect runtime behavior.',
});
}
return risks;
}Give these risks to the model. Do not make the model rediscover obvious things from scratch.
Step 4: List tests run and missing tests separately
This is one of the most important safety rules. Do not mix "tests that exist" with "tests that were run." A PR may include test files but CI may fail, and a developer may add tests but not run them locally. The assistant should be precise.
Example summary section:
Tests found in diff:
- Added tests/Feature/Billing/PaymentRetryServiceTest.php
Tests reported by CI:
- php artisan test: passed
- vendor/bin/phpstan analyse: passed
Potential missing tests:
- No test found for retry behavior when attempts = 3.
- No test found for unknown gateway error codes.To support this, collect CI data separately:
{
"ci": {
"status": "passed",
"checks": [
{
"name": "php artisan test",
"status": "passed",
"duration_seconds": 84
},
{
"name": "phpstan",
"status": "passed",
"duration_seconds": 31
}
]
}
}Then instruct the model:
Only list a test under "Tests run" if it appears in the CI data or user-provided command output.
If test data is missing, write: "No test run information was provided."This prevents fake certainty.
Step 5: Explain migrations like a production engineer
Database migrations deserve special treatment. A summary should explain what table changes, whether columns are added, removed, renamed, or indexed, whether the migration may lock a large table, whether backfill is involved, whether rollback is safe, and whether application code depends on the migration order.
For example, this migration is not just "adds an index":
Schema::table('orders', function (Blueprint $table) {
$table->index(['user_id', 'created_at']);
});A safer summary says:
Migration note:
- Adds a compound index on orders(user_id, created_at).
- This can improve queries that filter by user and sort/filter by creation date.
- On large orders tables, index creation may be slow or require an online migration strategy depending on the database engine and deployment setup.The assistant does not need to pretend it knows table size. It should say what must be checked.
Step 6: Create structured output
Structured output makes PR summaries easier to review and validate. Use a schema:
import { z } from 'zod';
const PullRequestSummarySchema = z.object({
overview: z.string(),
changedBehavior: z.array(z.string()),
reviewerFocus: z.array(z.string()),
riskyFiles: z.array(z.object({
file: z.string(),
reason: z.string(),
level: z.enum(['low', 'medium', 'high']),
})),
testsFound: z.array(z.string()),
testsRun: z.array(z.string()),
missingTests: z.array(z.string()),
migrationNotes: z.array(z.string()),
unknowns: z.array(z.string()),
});Then render it as Markdown:
function renderSummary(summary: z.infer<typeof PullRequestSummarySchema>): string {
return `
## Summary
${summary.overview}
## Changed behavior
${summary.changedBehavior.map(item => `- ${item}`).join('\n')}
## Reviewer focus
${summary.reviewerFocus.map(item => `- ${item}`).join('\n')}
## Risky files
${summary.riskyFiles.map(risk => `- **${risk.level}**: \`${risk.file}\` — ${risk.reason}`).join('\n')}
## Tests
**Tests found:**
${summary.testsFound.map(item => `- ${item}`).join('\n') || '- None found'}
**Tests run:**
${summary.testsRun.map(item => `- ${item}`).join('\n') || '- No test run information was provided'}
**Potential missing tests:**
${summary.missingTests.map(item => `- ${item}`).join('\n') || '- None detected'}
## Migration notes
${summary.migrationNotes.map(item => `- ${item}`).join('\n') || '- No migration notes'}
## Unknowns
${summary.unknowns.map(item => `- ${item}`).join('\n') || '- None'}
`;
}This output is predictable. Reviewers know where to look.
Step 7: Make the assistant admit uncertainty
A safe assistant must be allowed to say "I do not know." That is not weakness. That is a safety feature.
Examples:
Unknowns:
- The diff changes retry behavior, but no gateway documentation was provided to confirm the recoverable error list.
- No CI result was provided, so tests run cannot be verified.
- The migration adds an index to orders, but table size is unknown.This helps reviewers focus. A summary that claims everything is fine is less useful than a summary that highlights uncertainty.
Step 8: Avoid dangerous summary language
Do not let the assistant write:
This PR is safe to merge.That is not the assistant's decision. Better:
No blocker was detected from the provided diff and CI data, but human review is still required.Do not write:
All edge cases are covered.Better:
The diff includes tests for the main success path and max retry count. No test was found for unknown gateway error codes.Safe wording matters because summaries shape reviewer trust.
Step 9: Add repository-specific instructions
Generic summaries are okay. Repository-specific summaries are better. Create a file like this:
# AI PR Summary Instructions
For this repository:
- Treat changes under app/Billing as high risk.
- Treat changes under app/Auth as high risk.
- Mention database migrations clearly.
- Mention queue/job changes because they may affect async behavior.
- Do not say tests passed unless CI data confirms it.
- Always include reviewer focus.
- Keep the summary concise and technical.The assistant should read this file before summarizing. This turns team knowledge into a repeatable rule.
Step 10: Keep humans in control
AI-generated PR summaries should help reviewers. They should not replace review. The final summary can include a clear note:
Generated summary based on the PR diff and available CI data. Please verify behavior and risk before merging.This is honest and useful.
A complete workflow
Here is a practical flow:
1. Pull request opens.
2. System collects changed files, diff stats, and CI results.
3. Deterministic classifier marks risky areas.
4. AI receives curated diff context, risk metadata, and repository instructions.
5. AI returns structured JSON.
6. System validates JSON schema.
7. System renders Markdown summary.
8. Summary is posted as a PR comment or used to update the PR description.
9. Human reviewer reviews the PR.This flow is safe because the AI is not operating in a vacuum. It is grounded in facts.
Final thoughts
AI-generated pull request summaries can be genuinely helpful, but they must be designed for review, not for decoration.
A safe PR summary is evidence-based. It separates changed behavior from changed files. It separates tests found from tests run. It highlights risky files. It explains migrations. It admits unknowns. It avoids claiming approval.
That is the difference between a pretty summary and a useful engineering tool. The best AI PR assistant does not say, "Trust me." It says, "Here is what changed, here is why it matters, here is what needs your attention." That is exactly what reviewers need.
Further reading
- GitHub Copilot PR summaries: https://docs.github.com/copilot/using-github-copilot/creating-a-pull-request-summary-with-github-copilot
- Responsible use of GitHub Copilot pull request summaries: https://docs.github.com/en/copilot/responsible-use/pull-request-summaries
- OpenAI production best practices: https://developers.openai.com/api/docs/guides/production-best-practices





