
So, you've sat in a meeting where someone proudly announced they're "moving to microservices," and a senior architect across the table muttered, "That's just SOA with better marketing."
They're both half-right.
Service-Oriented Architecture and microservices share the same core idea: take a big system, slice it into smaller services, give each one a contract, and let them talk over the network. That insight is genuinely the same. The disagreement is in everything that comes next: how you describe those contracts, who governs them, how the services find each other, what's in the middle, and who owns the data.
The difference isn't just technical. It's a different theory of how organizations should build software. SOA was designed for companies where central architects controlled the standards and integration was an enterprise concern. Microservices were designed for product teams that wanted to ship without asking permission.
Let's break it down.
Where SOA Came From
SOA didn't appear out of nowhere. It came from a real, painful era: the late 90s and early 2000s, when "the system" at most large enterprises was actually dozens of systems. A mainframe holding customer records. A SQL Server running billing. A separate package for HR. A vendor product for shipping. A custom Java application stitched on top of all of it.
These systems didn't speak the same language. They didn't share a database. Some of them barely had APIs. And the business kept asking for things that crossed all of them: "When a customer updates their address in the CRM, also update it in billing, and trigger a verification email, and log it for compliance."
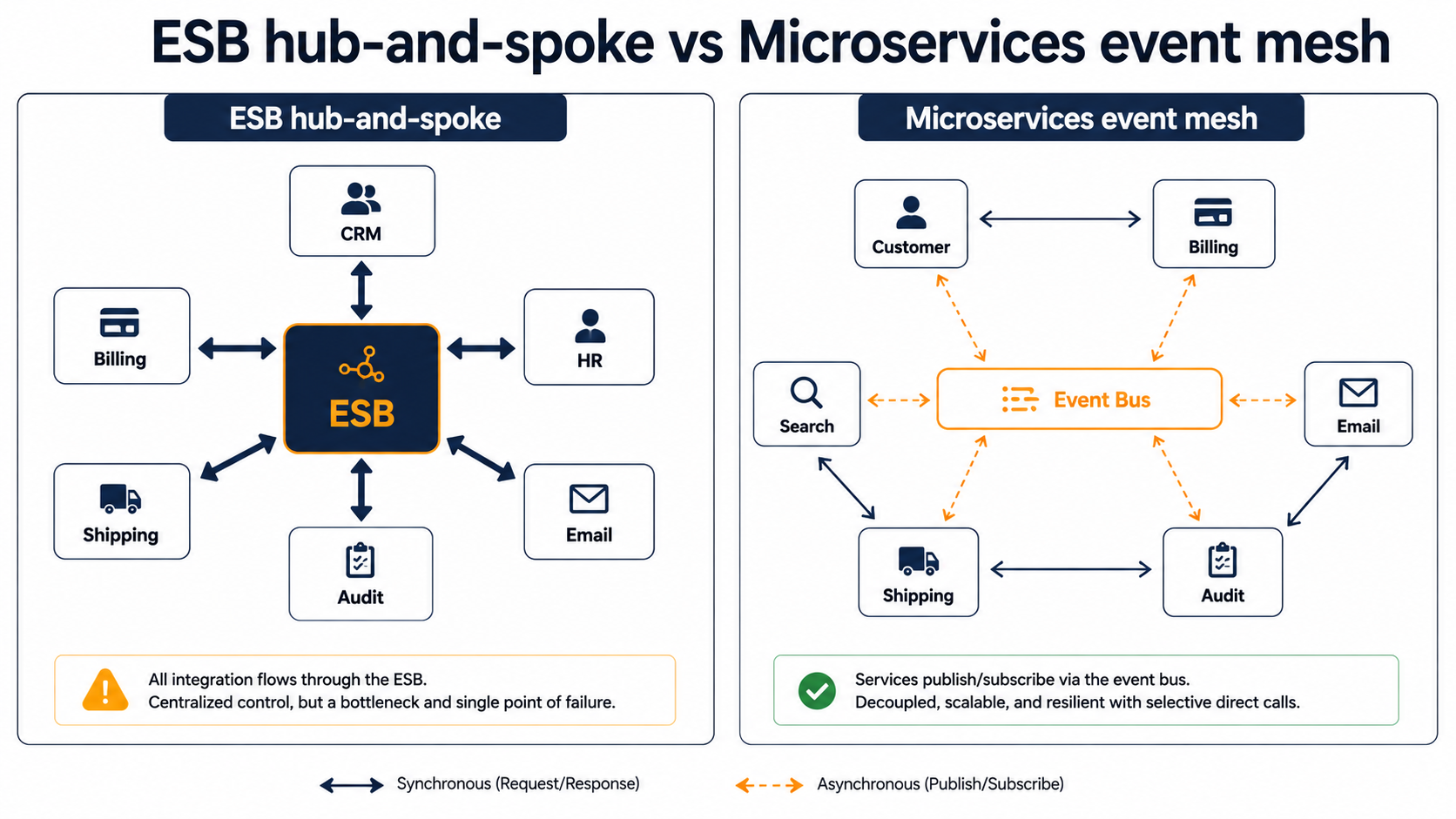
SOA was the response. The pitch was: stop integrating point-to-point. Wrap each system in a service. Define formal contracts. Route everything through a central piece of infrastructure that knows how to translate, transform, and orchestrate between them. That central piece became the Enterprise Service Bus, the ESB.
For a while, this worked. ESB products like IBM WebSphere, TIBCO BusinessWorks, MuleSoft (in its earlier ESB-shaped form), Oracle Service Bus, and Microsoft BizTalk Server became standard kit at banks, insurance companies, telcos, and governments. The contracts were typically SOAP-based, described in WSDL, and standardized across the enterprise.
Here's what a SOAP message envelope actually looks like. The verbosity is part of the story:
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:cust="http://example.com/customer">
<soap:Header>
<cust:Auth>
<cust:Token>eyJ...</cust:Token>
</cust:Auth>
</soap:Header>
<soap:Body>
<cust:UpdateAddressRequest>
<cust:CustomerId>4421</cust:CustomerId>
<cust:Address>
<cust:Street>15 Maple Lane</cust:Street>
<cust:City>Toronto</cust:City>
<cust:PostalCode>M4B 1B3</cust:PostalCode>
<cust:Country>CA</cust:Country>
</cust:Address>
</cust:UpdateAddressRequest>
</soap:Body>
</soap:Envelope>That envelope might pass through the ESB on its way from the CRM to billing, get transformed into a different shape that billing's WSDL expects, get routed in parallel to the email service, and get logged to an audit channel, all configured centrally, often through drag-and-drop tooling, by an integration team that wasn't on either side of the contract.
That last bit is important: SOA assumed integration was its own discipline.
Where Microservices Came From
Microservices grew up in a different environment. Around 2011-2014, a handful of consumer-internet companies (Netflix, Amazon, SoundCloud, Spotify) started talking publicly about how they'd broken their monoliths apart. The motivation wasn't enterprise integration. It was deployment speed.
These companies didn't have the legacy systems problem SOA was solving. They had a different problem: a single codebase that hundreds of engineers were trying to deploy at the same time, where one team's bug blocked everyone else's release, and the build took an hour.
So they decomposed for a different reason. They wanted small services that small teams could own end-to-end and ship independently. The contracts could be lightweight, usually JSON over HTTP, sometimes gRPC later on. There was no central bus, because no one wanted a central choke point. There was no enterprise-wide canonical data model, because each team was happy defining the schema that fit their bounded context.
The same address-update operation in a microservices world might look like this:
PUT /customers/4421/address HTTP/1.1
Host: api.customer-service.internal
Content-Type: application/json
Authorization: Bearer eyJ...
{
"street": "15 Maple Lane",
"city": "Toronto",
"postal_code": "M4B 1B3",
"country": "CA"
}After the customer service writes that, it doesn't call billing or email directly. It publishes an event to a broker:
{
"event_type": "CustomerAddressChanged",
"event_id": "evt_01HXY...",
"occurred_at": "2022-03-05T14:22:11Z",
"customer_id": 4421,
"address": {
"street": "15 Maple Lane",
"city": "Toronto",
"postal_code": "M4B 1B3",
"country": "CA"
}
}Whoever cares about address changes (billing, the verification service, the audit logger) subscribes. The customer service doesn't know they exist. That's not a missing feature. That's the whole point.
The Same Core Idea: Services With Contracts
Strip away the era and the tooling, and the foundational move is identical: decompose the system into services, and let them communicate through explicit contracts instead of shared databases or in-process function calls.
Both architectures ban two things that monoliths quietly allow: reaching into another module's tables, and assuming you'll always be deployed together. Both replace those with a contract: a formal description of what one service can ask another for, and what it'll get back.
That contract gives you the same things in either world:
- A unit of independent change, where a team can rewrite the inside of their service without breaking callers.
- A unit of independent deployment, where you can push one service without coordinating a whole-system release.
- A unit of independent scaling, where the parts that need more CPU or RAM get their own boxes.
- A unit of fault isolation, where one service falling over doesn't necessarily take the rest down with it.
Anyone who's done either architecture seriously has had this conversation: "We agreed on a contract, we deploy independently, we own our own data, what changed?" And the answer is: how the contract is defined, who owns it, what sits between services, and how much you've decentralized.
Where The Execution Diverges
This is where the architectures actually fight.
Contracts: heavy and formal vs lightweight and evolving
SOA contracts are typically WSDL, an XML document that describes every operation, every type, every fault, with strict schemas. WSDL is generated, not handwritten, and clients are typically generated from it: you point a tool at the WSDL URL and it produces a strongly-typed client class in your language. That gives you compile-time safety, but it also gives you compile-time coupling: change a field, regenerate everyone.
Microservices contracts are usually one of three shapes:
- OpenAPI (formerly Swagger) describing JSON-over-HTTP endpoints, often hand-edited or generated from code annotations.
- Protocol Buffers for gRPC, which look superficially like WSDL (strict schema, generated clients) but evolve more carefully (add fields, never reuse field numbers).
- Plain JSON with a documented but loose contract, which is more common than people admit.
A WSDL fragment for that customer service:
<wsdl:operation name="UpdateAddress">
<wsdl:input message="tns:UpdateAddressRequest"/>
<wsdl:output message="tns:UpdateAddressResponse"/>
<wsdl:fault name="InvalidAddress" message="tns:InvalidAddressFault"/>
<wsdl:fault name="CustomerNotFound" message="tns:CustomerNotFoundFault"/>
</wsdl:operation>The same contract in OpenAPI:
paths:
/customers/{customerId}/address:
put:
summary: Update a customer's primary address
parameters:
- in: path
name: customerId
required: true
schema: { type: integer }
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/Address'
responses:
'200': { description: Updated }
'404': { description: Customer not found }
'422': { description: Invalid address }Or in Protocol Buffers:
service Customer {
rpc UpdateAddress (UpdateAddressRequest) returns (UpdateAddressResponse);
}
message UpdateAddressRequest {
int64 customer_id = 1;
Address address = 2;
}
message Address {
string street = 1;
string city = 2;
string postal_code = 3;
string country = 4;
}Same operation, three philosophies. WSDL says: the contract is the source of truth, generate everything from it. OpenAPI says: the contract is documentation that should match the code. Protobuf says: the contract is a versioned schema that evolves with explicit rules.
The execution diverges at evolution. SOA contracts often required coordinated upgrades: change the WSDL, push new clients to all consumers, deploy in lockstep. Microservices contracts are designed for additive change: add fields without breaking old clients, deprecate carefully, support multiple versions in flight. That's not because microservices people are smarter; it's because they have to. There's no central team to coordinate the lockstep.
Governance: top-down committee vs federated teams
This is the cultural fault line.
SOA governance is centralized. There's an architecture team. They define the canonical data model: one agreed-upon shape for "Customer" across the entire enterprise, with every system mapping in and out of it. They review every new service for compliance. They decide which protocols are allowed, which fields go in the canonical Customer, and which integration patterns are blessed.
This isn't bureaucracy for its own sake. In a real enterprise (a bank with regulatory obligations, an insurance company with data lineage requirements, a hospital chain with compliance rules), central governance is how you stay out of trouble.
Microservices governance is federated. Each team owns their own service end-to-end: the schema, the language, the database, the deployment, the on-call rotation. There's usually still a platform team that defines guardrails (authentication, observability, the message bus), but they don't pre-approve schemas. The phrase Amazon's CTO Werner Vogels made famous was "you build it, you run it", and the implicit corollary is "you also design it."
Both models break in opposite ways. Centralized governance breaks when the central team becomes a bottleneck: every new service waits weeks for review, every schema change spawns a meeting. Federated governance breaks when nobody owns the cross-cutting concerns: three teams independently invent three different "Customer" shapes, and now there's no single place to ask "what's a customer?". The drift is real.
Integration: smart pipes vs dumb pipes
Martin Fowler and James Lewis coined the phrase that still does most of the work for the microservices half here: smart endpoints and dumb pipes. The SOA inversion is the mirror image: smart endpoints behind smart pipes, with the ESB carrying the routing, transformation, and orchestration that microservices push out to the edges.
In SOA, the ESB is smart. It knows how to:
- Route a message based on its content.
- Transform XML payloads from one schema to another.
- Translate between SOAP and JMS and FTP and database stored procedures.
- Orchestrate multi-step workflows (often via BPEL).
- Apply enterprise-wide policies (auth, throttling, audit logging) in one place.
The pipe does the hard work, so the services can be small and dumb at the edges.
In microservices, the bus is dumb. Kafka, RabbitMQ, Google Pub/Sub, NATS: they move bytes from a producer to a subscriber. They don't know what's in the message. They don't transform it. They don't orchestrate workflows. If you need to coordinate three services, you do it with choreography (each service reacts to events and emits its own), or with a workflow engine running outside the bus (Temporal, Airflow, Step Functions).
A SOA-era integration might be configured in the ESB itself, in something like:
<route id="customer-address-changed">
<from uri="soap:CustomerService/UpdateAddress"/>
<transform xslt="customer-to-canonical.xsl"/>
<multicast>
<to uri="soap:BillingService/UpdateBillingAddress"/>
<to uri="jms:queue/email-verification"/>
<to uri="db:audit/insert-address-change"/>
</multicast>
</route>Same intent in a microservices world looks like nothing in particular, because the customer service just publishes an event:
def update_address(customer_id: int, address: Address) -> None:
repo.save_address(customer_id, address)
bus.publish("CustomerAddressChanged", {
"customer_id": customer_id,
"address": address.to_dict(),
"occurred_at": now_utc().isoformat(),
})And each downstream service quietly subscribes. The integration logic isn't centralized; it's distributed across the consumers. Whoever cares, listens.
The trade-off is real in both directions. The ESB approach gives you one place to see what happens when the address changes; the microservices approach gives you three independently-owned consumers that nobody can break by editing a central config. Both are valid. They optimize for different things.
Data ownership: shared canonical vs bounded contexts
SOA encouraged a canonical data model at the enterprise level. One agreed-upon "Customer" shape. Everyone maps into and out of it. The advantage: cross-system reports and analytics get easier, because everything speaks the same dialect. The disadvantage: that canonical model is a contract that everyone has to maintain forever, and it tends to grow into a 200-field god-object that nobody fully understands.
Microservices, influenced heavily by Domain-Driven Design, push the opposite: bounded contexts. The marketing service's "Customer" has a name, an email, and a campaign history. The billing service's "Customer" has a name, a billing address, and a payment method. The support service's "Customer" has a name, a tier, and an open-ticket count. They're not the same object. They share an ID. That's it. Each context owns the shape that fits its domain.
This is genuinely better in most product environments and genuinely worse in some enterprise reporting scenarios. The federated, per-context shape lets product teams move fast. It also makes the question "give me a single sheet with every customer's full information" annoyingly hard to answer without a downstream data warehouse that re-joins everything. There's no free lunch.
Deployment and runtime: shared infra vs independent
SOA services often shared infrastructure: an application server (WebLogic, WebSphere, JBoss) hosting many services in the same JVM, a shared database with separate schemas per service, a deployment that pushed multiple services together because they ran on the same box.
Microservices ran in the opposite direction: each service in its own container, its own database, its own deployment pipeline. The cloud-and-Docker era was the technology that made this cheap. Without containers and orchestrators, the microservices style would still be theoretically possible but practically painful, and a lot of pre-2014 attempts at fine-grained services failed precisely because the deployment overhead was crushing.
This is one place where execution genuinely depended on what the surrounding ecosystem made cheap. SOA-era infrastructure made shared hosting natural; microservices-era infrastructure made independent hosting natural. The architectural choice and the deployment substrate co-evolved.
The Cultural Shift That Made The Difference
If you stop at the technical comparison, you miss the actual story. The shift from SOA to microservices wasn't really about XML versus JSON, or SOAP versus REST, or ESBs versus message brokers. It was about who's allowed to make decisions.
SOA assumed a world where:
- A central architecture group defines the standards.
- An integration team owns the bus and the mappings.
- A separate operations team runs the production services.
- Product teams build features within that framework.
Microservices assumed a world where:
- Each product team owns a slice end-to-end.
- The platform team provides paved roads (auth, observability, the bus, the deployment pipeline) but doesn't gate releases.
- Operations is part of the product team's job, not a separate function.
- Standards emerge bottom-up and are encoded as defaults in the platform, not as committee mandates.
You can run microservices in a SOA-era organizational structure, and you'll discover quickly that it doesn't work: the bottlenecks reappear, just dressed in JSON. You can run SOA in a startup-style team structure, and you'll discover that without central governance, the canonical model never stabilizes and the bus becomes a graveyard of half-supported routes.
Conway's Law isn't a footnote here. It's the headline. The architecture you can actually run is the architecture your organization is shaped to support.
When SOA Patterns Still Make Sense
It's tempting to treat SOA as a museum piece, but that's a mistake. Several SOA patterns are alive and well, sometimes under new names:
- Centralized API gateways doing auth, rate limiting, and request transformation are an ESB-shaped pattern, just at the edge instead of the middle.
- Service meshes (Istio, Linkerd) bring back the "smart pipes" idea for east-west traffic, except instead of one central bus, the smart logic runs as a sidecar next to each service. Same goal, different topology.
- Workflow orchestrators (Temporal, Camunda, AWS Step Functions) are a reincarnation of BPEL: long-running orchestrated workflows, version-aware, durable. The need didn't go away.
- Canonical event schemas in mature microservices estates are the federated cousin of the canonical data model: same insight (we need a shared vocabulary), different governance model.
If you're working in a regulated enterprise and you're tempted to wave the microservices flag at every problem, slow down. The reasons SOA emphasized central governance (auditability, standardization, controlled change) haven't gone away just because the tooling has. The right answer might be "microservices for the product surface, SOA-style governance for the regulated core."
So, Same Or Different?
Same idea: services with contracts, replacing in-process calls and shared databases.
Different execution: how you describe the contracts, who owns them, what's in the middle, who governs the standards, and how independent each team is allowed to be.
The mistake people make in both directions is treating one as obviously superior to the other. Microservices won the public conversation, but SOA solved real problems for real organizations and many of those problems are still problems. The pendulum swings, the labels change, the underlying engineering trade-offs stay where they were.
Pick the one your organization can actually staff and operate. That's the whole game.





