You've probably written this test before.
func TestAdd(t *testing.T) {
if got := Add(1, 2); got != 3 {
t.Errorf("Add(1, 2) = %d, want 3", got)
}
if got := Add(0, 0); got != 0 {
t.Errorf("Add(0, 0) = %d, want 0", got)
}
if got := Add(-1, 1); got != 0 {
t.Errorf("Add(-1, 1) = %d, want 0", got)
}
}Three cases. Already the same five lines copied three times. Now imagine you need to test fifteen cases, and the function under test takes a struct, and the error path matters as much as the happy path.
You'll either give up and test two of them, or you'll write a test file that looks like a copy-paste graveyard.
Go has a cleaner answer, and it's the closest thing the standard library has to an officially-blessed style: the table-driven test. The Go team uses it across the standard library, the testing wiki recommends it, and once you write one you stop reaching for anything else.
Let's break it down properly, not just the skeleton, but how it scales when the function under test gets uglier.
The pattern in one sentence
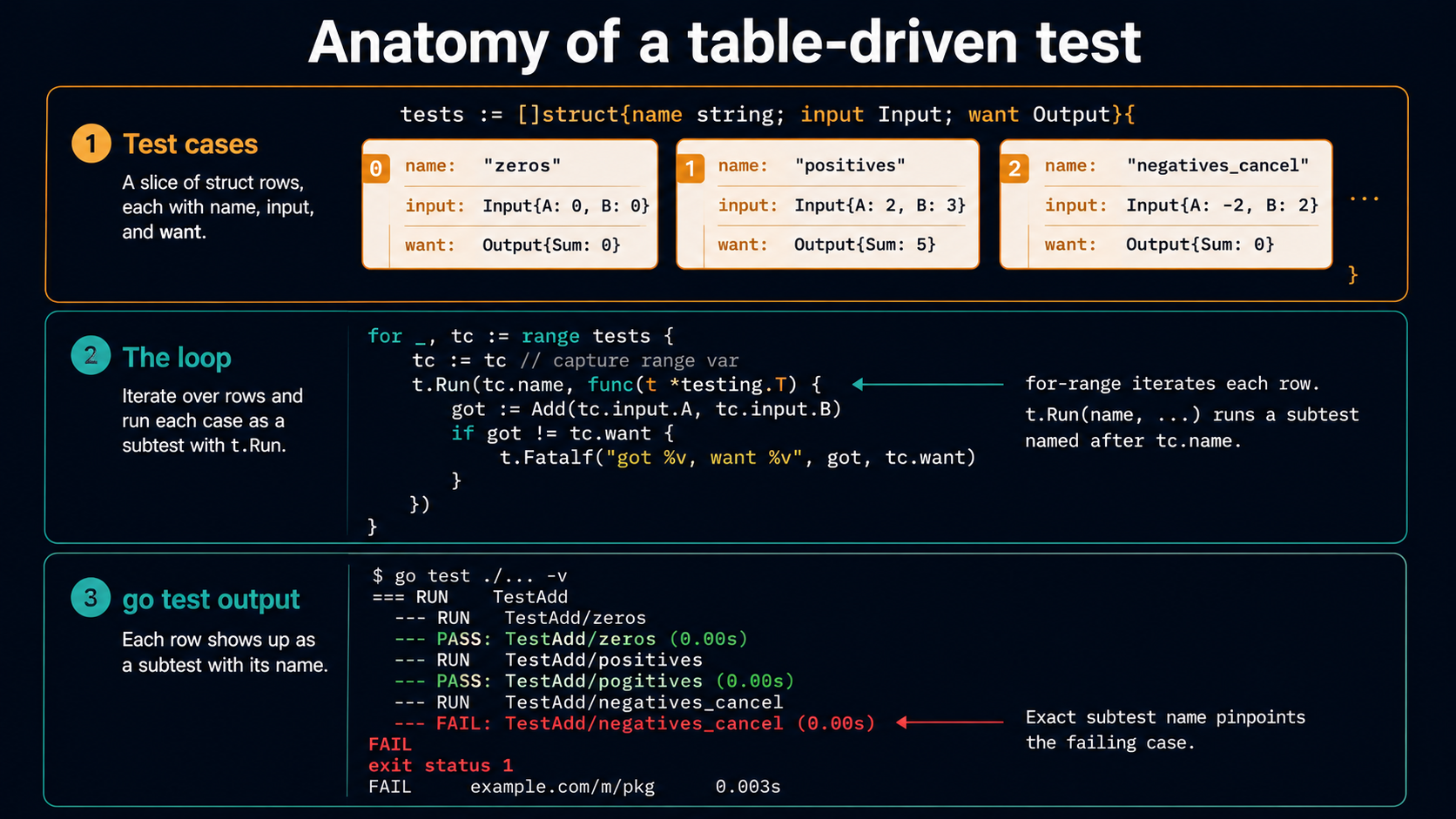
A table-driven test is a slice of test-case structs, looped over with t.Run, where each iteration calls the function under test and asserts on the result.
That's it. The pattern is small. The interesting part is what you put in the struct, and how you grow it as the function grows.
Here's the same Add test, but as a table:
func TestAdd(t *testing.T) {
tests := []struct {
name string
a, b int
want int
}{
{"positive numbers", 1, 2, 3},
{"zeros", 0, 0, 0},
{"negatives cancel", -1, 1, 0},
{"both negative", -2, -3, -5},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := Add(tt.a, tt.b); got != tt.want {
t.Errorf("Add(%d, %d) = %d, want %d", tt.a, tt.b, got, tt.want)
}
})
}
}Same coverage, fewer lines, and now adding a fifth case is one line of struct literal instead of five lines of if got != ... { t.Errorf(...) }.
But the real payoff isn't line count. It's what happens when one case fails.
Why t.Run changes everything
The t.Run(tt.name, ...) wrapper isn't decorative. It creates a subtest, and Go's test runner treats subtests as first-class.
When negatives cancel fails, the output is:
--- FAIL: TestAdd (0.00s)
--- FAIL: TestAdd/negatives_cancel (0.00s)
add_test.go:18: Add(-1, 1) = 1, want 0You see exactly which case broke, by name. You can run only that one case during a debug loop:
go test -run 'TestAdd/negatives_cancel' ./...You can run a family of cases with a regex:
go test -run 'TestAdd/negatives' ./...Without t.Run, all your cases share a single TestAdd, and the failure tells you "something in here broke" with a line number that doesn't point to the case; it points to the assertion. With twenty cases, that's miserable. With two hundred cases (which happens), it's a productivity sink.
The t.Run wrapper is what turns a slice of cases into a real, debuggable, filterable test.
A more honest example: validating an email
Add is a toy. Let's table-drive something that resembles real work: an email validator with a few real edge cases.
package email
import (
"errors"
"strings"
)
var (
ErrEmpty = errors.New("email is empty")
ErrNoAt = errors.New("email is missing @")
ErrMultipleAt = errors.New("email has more than one @")
ErrLocalEmpty = errors.New("local part is empty")
ErrDomainEmpty = errors.New("domain part is empty")
)
func Validate(addr string) error {
addr = strings.TrimSpace(addr)
if addr == "" {
return ErrEmpty
}
parts := strings.Split(addr, "@")
switch len(parts) {
case 1:
return ErrNoAt
case 2:
if parts[0] == "" {
return ErrLocalEmpty
}
if parts[1] == "" {
return ErrDomainEmpty
}
return nil
default:
return ErrMultipleAt
}
}Six error cases plus one happy path. Without a table, that's seven separate test functions or one giant function with seven branches. With a table:
func TestValidate(t *testing.T) {
tests := []struct {
name string
input string
wantErr error
}{
{"valid email", "hello@example.com", nil},
{"trims whitespace", " hello@example.com ", nil},
{"empty string", "", ErrEmpty},
{"only whitespace", " ", ErrEmpty},
{"missing @", "helloexample.com", ErrNoAt},
{"two @ signs", "hello@@example.com", ErrMultipleAt},
{"empty local", "@example.com", ErrLocalEmpty},
{"empty domain", "hello@", ErrDomainEmpty},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
err := Validate(tt.input)
if !errors.Is(err, tt.wantErr) {
t.Errorf("Validate(%q) error = %v, want %v", tt.input, err, tt.wantErr)
}
})
}
}Notice the errors.Is instead of err == tt.wantErr. That's not a stylistic thing; it's the correct way to compare errors in modern Go, because it walks the wrapping chain. If your code grows to return fmt.Errorf("validate: %w", ErrNoAt) later, the test keeps passing without changes.
Also notice the case names are sentences, not snake_case. Go's runner converts spaces to underscores in the path (TestValidate/two_@_signs), but the source reads like documentation. When the test file grows, those names are the docs.
Functions that return more than one thing
Pure validators are easy. Real functions return a value and an error, and you want to assert both.
Say you're parsing a duration string in a custom format: "1h30m", "45s", that kind of thing, into a time.Duration.
func TestParseDuration(t *testing.T) {
tests := []struct {
name string
input string
want time.Duration
wantErr bool
}{
{"hours only", "2h", 2 * time.Hour, false},
{"minutes only", "30m", 30 * time.Minute, false},
{"hours and minutes", "1h30m", 90 * time.Minute, false},
{"empty string", "", 0, true},
{"junk", "abc", 0, true},
{"negative", "-1h", -time.Hour, false},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
got, err := ParseDuration(tt.input)
if (err != nil) != tt.wantErr {
t.Fatalf("ParseDuration(%q) err = %v, wantErr = %v", tt.input, err, tt.wantErr)
return
}
if got != tt.want {
t.Errorf("ParseDuration(%q) = %v, want %v", tt.input, got, tt.want)
}
})
}
}Two assertions per case. The t.Fatalf (not t.Errorf) on the error check is important: if the error state doesn't match, you don't want to keep going and compare the value too. That comparison is meaningless.. Fatalf stops the current subtest, not the whole TestParseDuration. Other cases keep running.
This is one of the subtle reasons t.Run matters. Without it, Fatalf aborts every remaining case in the file. With it, each case is independent.
When the input gets complex
So far the inputs have been a single string or two ints. Real code takes structs.
Say you're testing a discount calculator that takes a cart and a coupon:
type Cart struct {
Subtotal float64
Items int
}
type Coupon struct {
Code string
PercentOff float64
MinSubtotal float64
MinItems int
}
func Apply(cart Cart, coupon Coupon) (float64, error) {
if cart.Subtotal < coupon.MinSubtotal {
return cart.Subtotal, ErrBelowMinimum
}
if cart.Items < coupon.MinItems {
return cart.Subtotal, ErrTooFewItems
}
discount := cart.Subtotal * (coupon.PercentOff / 100)
return cart.Subtotal - discount, nil
}The table grows wider, but the pattern is identical:
func TestApply(t *testing.T) {
summer10 := Coupon{Code: "SUMMER10", PercentOff: 10, MinSubtotal: 0, MinItems: 0}
bulk20 := Coupon{Code: "BULK20", PercentOff: 20, MinSubtotal: 100, MinItems: 5}
tests := []struct {
name string
cart Cart
coupon Coupon
want float64
wantErr error
}{
{
name: "10 percent off small cart",
cart: Cart{Subtotal: 50, Items: 1},
coupon: summer10,
want: 45,
},
{
name: "bulk coupon rejects small subtotal",
cart: Cart{Subtotal: 50, Items: 10},
coupon: bulk20,
want: 50,
wantErr: ErrBelowMinimum,
},
{
name: "bulk coupon rejects few items",
cart: Cart{Subtotal: 200, Items: 2},
coupon: bulk20,
want: 200,
wantErr: ErrTooFewItems,
},
{
name: "bulk coupon applies to qualifying cart",
cart: Cart{Subtotal: 200, Items: 6},
coupon: bulk20,
want: 160,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
got, err := Apply(tt.cart, tt.coupon)
if !errors.Is(err, tt.wantErr) {
t.Fatalf("err = %v, want %v", err, tt.wantErr)
}
if got != tt.want {
t.Errorf("total = %v, want %v", got, tt.want)
}
})
}
}Two things changed and both are deliberate.
First, the coupons are declared as variables above the table, not inlined into every row. When you want to test ten cases against the same bulk20 coupon, you don't want to repeat its definition ten times. Variables before the table; cases use them.
Second, the struct literal uses named fields. Cart{Subtotal: 50, Items: 1} instead of Cart{50, 1}. Once a struct has more than two fields, positional initialisation is unreadable and dangerous: swap two arguments and the test still compiles, just lies.
Floating-point comparison: a small but important detour
got != tt.want worked for ints and for clean fractions like 45.0. The moment you do real math, it stops working.
0.1 + 0.2 == 0.3 // falseIf your code multiplies, divides, or accumulates floats, compare with a tolerance:
const epsilon = 1e-9
if diff := got - tt.want; diff > epsilon || diff < -epsilon {
t.Errorf("total = %v, want %v (diff %v)", got, tt.want, diff)
}For most real test suites that's enough. If you're testing financial code with two decimal places of precision, epsilon = 0.005 makes more sense. If you're doing scientific work, you probably want math.Abs(got - want) / math.Abs(want) < relativeTolerance.
The point: don't write got != tt.want for floats and then chase the resulting flakes for a week.
Running cases in parallel
Go's test runner can run subtests in parallel. For table-driven tests, that often turns "8 cases in 400ms" into "8 cases in 60ms", which matters when the suite has hundreds of tests.
for _, tt := range tests {
tt := tt // capture range variable — see below
t.Run(tt.name, func(t *testing.T) {
t.Parallel()
// ... assertions
})
}Two lines you need to be careful about.
The first is tt := tt. In Go versions before 1.22, the loop variable tt was shared across iterations. If the subtest closure ran asynchronously, every case would see the last tt value. The result: tests that passed locally and failed in CI, or vice versa. The fix was to shadow tt inside the loop body, capturing it per iteration.
Go 1.22 changed loop-variable semantics so each iteration gets its own variable. If your go.mod declares go 1.22 or higher, you can drop the tt := tt line. If it doesn't, keep it. The line is harmless either way, so when in doubt, leave it in.
The second is t.Parallel() itself. Call it as the first line of the subtest. It signals to the runner: "you can pause me and run me alongside other parallel tests." Cases that share mutable state (a global, a temp file, a database) need synchronisation or they'll race. The race detector (go test -race) is how you catch that, so run it locally, run it in CI.
Setup, teardown, and helpers
Real tests need fixtures. Open a temp directory, start an in-memory database, create three sample users, that kind of thing. Two clean ways to handle it in table-driven tests.
The first is t.Helper() plus a setup function called per subtest:
func setupDB(t *testing.T) *DB {
t.Helper()
db := NewInMemoryDB()
t.Cleanup(func() { db.Close() })
return db
}
func TestUserRepo(t *testing.T) {
tests := []struct {
name string
seed []User
lookup string
want User
}{
// ...
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
db := setupDB(t)
for _, u := range tt.seed {
db.Insert(u)
}
got := db.Find(tt.lookup)
if got != tt.want {
t.Errorf("Find(%q) = %v, want %v", tt.lookup, got, tt.want)
}
})
}
}t.Helper() makes the failure point inside setupDB show up at the caller's line, not at the helper's line. Without it, every failure would point at the db := NewInMemoryDB() line, which is useless.
t.Cleanup registers a teardown function that runs after the test (or subtest) finishes, even if it failed. Cleaner than defer because cleanups stack properly when you have multiple helpers, and they survive across t.Run boundaries.
The second pattern is per-case setup hooks inside the struct:
tests := []struct {
name string
setup func(t *testing.T) *DB
lookup string
want User
}{
{
name: "finds existing user",
setup: func(t *testing.T) *DB {
db := setupDB(t)
db.Insert(User{ID: "u1", Name: "Ada"})
return db
},
lookup: "u1",
want: User{ID: "u1", Name: "Ada"},
},
}That trades brevity for flexibility. Useful when different cases need different seed data and you don't want a giant if-else inside the loop body. Use it sparingly: when most cases need the same setup, the helper-call-per-subtest version is cleaner.
Comparing structs and slices
Once your want is a struct or a slice, got != tt.want either won't compile (slices aren't comparable) or will compile but not give you a useful diff.
Two tools.
The standard-library option is reflect.DeepEqual:
if !reflect.DeepEqual(got, tt.want) {
t.Errorf("got %+v, want %+v", got, tt.want)
}It works, but the failure message is "here's the whole struct, find the difference yourself." Fine for small structs, painful for big ones.
The better option, if you can take an external dependency, is github.com/google/go-cmp/cmp:
import "github.com/google/go-cmp/cmp"
if diff := cmp.Diff(tt.want, got); diff != "" {
t.Errorf("mismatch (-want +got):\n%s", diff)
}cmp.Diff returns a colored, line-by-line diff of the two values. The failure tells you exactly which field changed, instead of dumping both blobs.
Note the argument order: cmp.Diff(want, got). The - prefix in the diff output marks the want side, the + marks the got side. Swap them and your brain has to do extra work every failure.
When the table goes wrong
The pattern is excellent, but it's not free. Here are the failure modes I keep seeing in real codebases.
The mega-table. One TestThing with sixty cases, three of which test error paths, one tests a corner case from a 2023 incident, twenty test integer overflow, the rest test the happy path. When something breaks, you read sixty rows to figure out which family of cases is affected. Split it: one TestThing_HappyPath, one TestThing_Errors, one TestThing_Overflow. Each table stays under fifteen-ish rows.
The struct that grew teeth. A test-case struct that started with three fields and now has fourteen. Half the cases use four fields, half use eleven. Empty fields stand in for "this doesn't apply here." If a struct gets that wide, the function under test is doing too much, or the test should be split by concern.
The unreadable name. {"case1", ...}, {"works", ...}, {"basic", ...}. When a case fails six months later, "case1" tells you nothing. Names should describe the scenario in a sentence: "rejects negative discount", "merges duplicate items", "preserves currency when total is zero".
Hidden mutation across cases. One case modifies a global, the next case fails because of it. Tables look stateless, just a slice of literals, but if the function under test pokes shared state, you'll find out. Either reset state in each t.Run, or scope the state to the subtest with t.Cleanup.
The over-clever helper. A runCase(t, tt) helper that hides the actual assertion. The whole point of the pattern is that the loop body is short and obvious. If the helper is bigger than the case data, you've optimised the wrong thing.
When not to use a table
Some tests don't want a table. Force one in and you make the test worse.
A test that exercises one specific sequence of steps: open a file, write three lines, seek to position 5, read the byte, assert. That sequence is not parametric. It's one scenario, not a family of cases. Just write the procedure.
A test that needs ten lines of setup between assertions probably doesn't fit either. The table form assumes "feed input, get output, compare." When the actual interaction is "do thing, observe state, do another thing, observe again," a regular linear test reads more honestly.
Property-based tests are another shape entirely. If you want "for any int n, Reverse(Reverse(n)) == n," reach for testing/quick or gopter, not a table of cases. Tables enumerate; property tests generate.
Golden files: when the want is too big to inline
Some functions produce big outputs: a formatted report, a generated SQL query, a serialized protobuf. Inlining a 200-line expected output into a struct literal is unreadable.
Go's idiom for this is the golden file. The expected output lives in testdata/<case>.golden, and the test reads it:
func TestFormatReport(t *testing.T) {
tests := []struct {
name string
input Report
}{
{"empty", Report{}},
{"one row", Report{Rows: []Row{{Name: "alice", Score: 42}}}},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
got := Format(tt.input)
golden := filepath.Join("testdata", tt.name+".golden")
if *update {
if err := os.WriteFile(golden, got, 0o644); err != nil {
t.Fatal(err)
}
}
want, err := os.ReadFile(golden)
if err != nil {
t.Fatal(err)
}
if !bytes.Equal(got, want) {
t.Errorf("output mismatch — run `go test -update` to refresh")
}
})
}
}
var update = flag.Bool("update", false, "update golden files")The -update flag pattern is a Go-team convention: when the expected output legitimately changes, you regenerate the goldens with go test -update, eyeball the diff in git diff testdata/, and commit. The diff review is the safety net: if a refactor accidentally changes the output, you see it before merging.
testdata/ is a special directory name: Go's tooling skips it during build but makes it available at test time. Use it.
A complete checklist for a healthy table test
When you're writing or reviewing one, look for:
- A
namefield, and the names read like sentences. t.Run(tt.name, ...)wrapping every assertion.errors.Isfor error comparison (not==), andcmp.Difforreflect.DeepEqualfor structs.t.Helper()on every test helper, so failures point at the right line.t.Cleanupfor teardown, notdefer; cleanups survive parents/children better.- Floats compared with a tolerance, not
==. t.Parallel()at the top of subtests where possible, withtt := ttifgo.modis older than 1.22.- The table under twenty rows. If it's longer, split it.
- The struct under eight fields. If it's wider, split it.
- Empty fields in the struct are rare. If half the rows have empty fields, you're testing different things in the same table.
The pattern is mechanical enough that you can recognise a healthy table-driven test in five seconds and a sick one just as fast. That's most of why it's the standard, and it makes review cheap.
Why this matters more than it looks
Tests are a place where small style choices compound. A test file you'll read fifty times (every time someone breaks it, every time the function changes, every time a new engineer joins) pays back every minute you spent making it readable.
Table-driven tests scale that readability. Adding a case is one line. Removing a case is one line. Finding the case that broke is the runner's job. New engineers learn the pattern once and apply it everywhere.
It's not the only way to write tests in Go, and it's not always the right one. But when it fits, and for most pure functions, validators, formatters, and small state machines it does, there's nothing else worth reaching for.
Open up the testing package source and grep for tests := []struct. The Go team uses this pattern in their own tests. So does most of the standard library. So do the tests in the projects you've probably read.
Once you've seen the shape a few times, you stop noticing it and just write it. That's when it's done its job.