
You've written the test. It passes locally. It passes in the dev branch. It passes the first time CI runs it. Then, two weeks later, in some unrelated PR, it fails. You re-run it. It passes. You add a console.log, it passes again. You remove the log, it fails. Eventually somebody adds it to the retry list, and everyone agrees not to look at it again.
Almost every flaky test I've ever debugged has been an async test that lied about being finished. Either a timer fired after the test had already returned, or a promise resolved in the next test's window, or the test runner moved on while a background callback was still in flight. The code under test was fine. The test was wrong.
Testing async code in Node well is mostly about being honest about when the work is done. Synchronous code finishes when the function returns. Async code finishes when… you actually have to think about it. This piece walks through the three failure modes that show up over and over, timers, promises, and cross-test races, and the patterns that turn flaky async tests into boring ones.
The Three Ways Async Tests Bite
Before any code, it helps to name the categories. They look different on the surface but the underlying mistake is the same: the test declared itself complete before the async work actually was.
Frozen timers. You replace real setTimeout with a fake clock to make a 5-second debounce testable, then forget that fake clocks don't advance themselves and your assertion runs against a state that hasn't been reached yet. Or you advance the clock, but the callback scheduled by that timer queues another promise, and you didn't flush the microtask queue afterwards, so the assertion fires before the second tick of work lands.
Missed microtasks. You await a function that fires off a fetch() and returns immediately. The fetch resolves on the next microtask. Your assertion runs before that microtask drains. The test passes when the network is fast and fails when it isn't, except there's no network, this is a mock, and "fast" depends on whether you await the mock's internal queue.
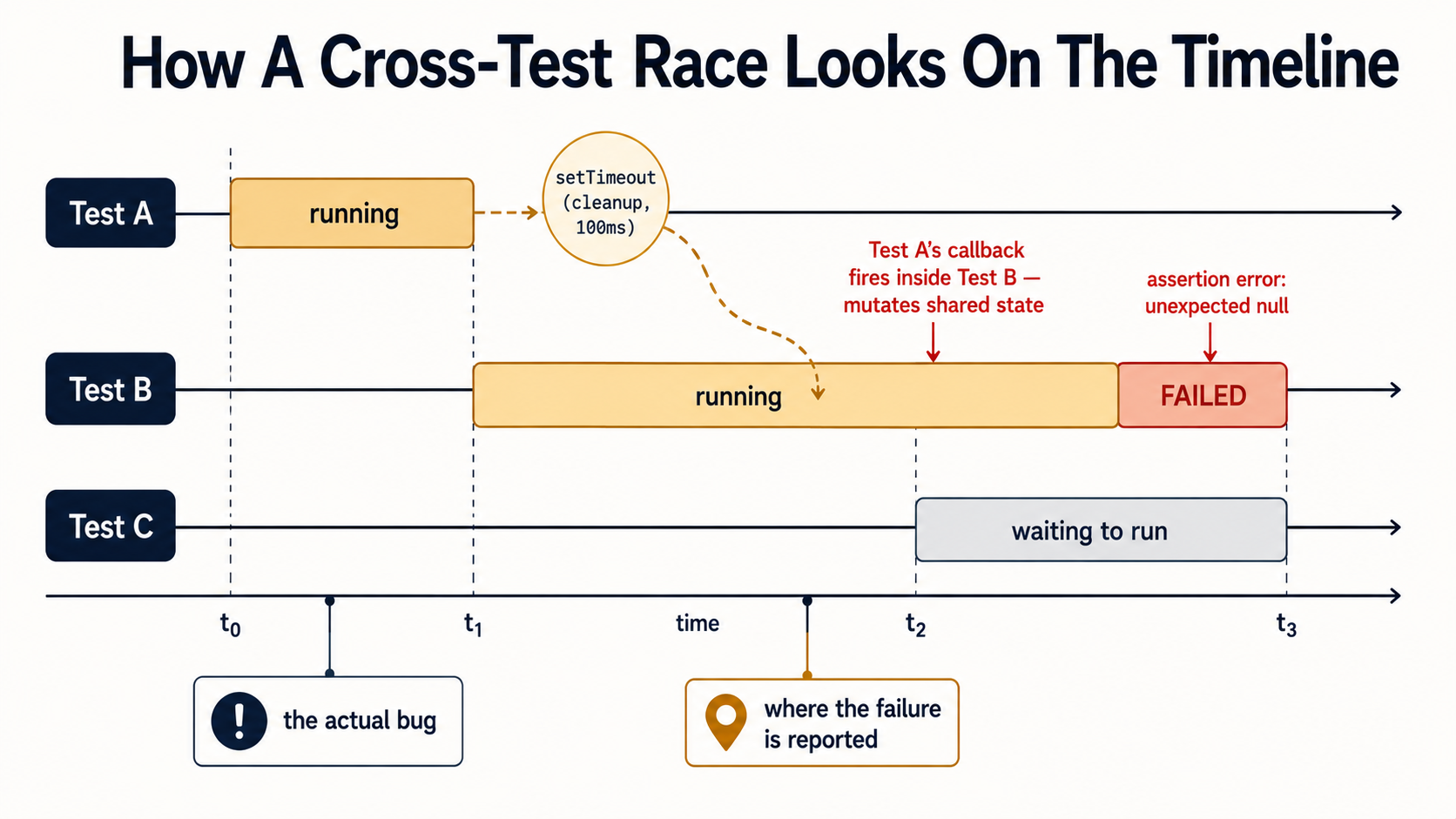
Cross-test races. Test A schedules a setTimeout(callback, 100) and returns. The test runner moves to Test B. Test A's callback fires inside Test B's window, mutates some module-level state Test B is asserting on, and Test B fails with an error that mentions nothing about Test A. This one is the worst, because reading the failing test tells you almost nothing about the real cause.
Each of these has a clean fix. Most teams' test suites have at least one of all three.
Real Timers Vs Fake Timers, And When Each One Hurts
Pick a side per test, and stick with it. Mixing real timers and fake timers inside a single test is where most timer bugs start.
Real timers are simple: the test takes as long as the timer says, and if you ask for setTimeout(..., 5000) you wait five seconds. That's fine for fast unit tests where the timeout is single-digit milliseconds and tells you something real about scheduling. It's terrible for testing a debounce, a retry-with-backoff, or a poll loop, because nobody wants a 60-second test suite for what should be 60ms of logic.
Fake timers are the right tool for that, but they come with two pitfalls that catch almost everyone the first time.
Pitfall 1: forgetting to advance the clock. A fake timer doesn't tick on its own. You install it, you schedule work against it, and then you tell it to advance. If you skip the advance, the work just sits in the queue forever, and your assertion runs against state that never updated.
import { describe, it, expect, vi, beforeEach, afterEach } from 'vitest';
import { debounce } from '../src/debounce.js';
describe('debounce', () => {
beforeEach(() => vi.useFakeTimers());
afterEach(() => vi.useRealTimers());
it('fires after the delay', () => {
const spy = vi.fn();
const debounced = debounce(spy, 200);
debounced('hello');
expect(spy).toHaveBeenCalledWith('hello'); // fails — clock never advanced
});
});The fix is one line. Tell the clock to move past the delay.
it('fires after the delay', async () => {
const spy = vi.fn();
const debounced = debounce(spy, 200);
debounced('hello');
await vi.advanceTimersByTimeAsync(200);
expect(spy).toHaveBeenCalledWith('hello');
});Two things matter in the working version. First, advanceTimersByTimeAsync is preferred over the synchronous advanceTimersByTime when the scheduled callback returns or awaits a promise. The synchronous version fires the timer but doesn't yield, so the promise scheduled inside the callback hasn't resolved when the next line of the test runs. The async version yields between phases so chained promises drain. Jest has the same split, jest.advanceTimersByTimeAsync versus jest.advanceTimersByTime, and the rule is identical.
Second, afterEach(vi.useRealTimers) is non-optional. Leaving a fake clock installed leaks into the next test, and the next test's setTimeout calls don't tick because there's still a paused clock that nobody knows about. This is one of the most common sources of "this test passes in isolation but fails when the file is run together."
Pitfall 2: faking timers your code actually needed real. Some libraries, and some Node internals, use timers for things you don't want frozen. setImmediate is used by certain stream and crypto operations. Date.now() is used by every logging library and probably by your application's own caching layer. If you blanket-fake everything, you can break code that has nothing to do with the unit under test.
Both Jest and Vitest let you opt out of specific timer APIs.
import { vi } from 'vitest';
beforeEach(() => {
vi.useFakeTimers({
toFake: ['setTimeout', 'setInterval', 'clearTimeout', 'clearInterval', 'Date'],
});
});
afterEach(() => vi.useRealTimers());beforeEach(() => {
jest.useFakeTimers({
doNotFake: ['setImmediate', 'queueMicrotask', 'process.nextTick'],
});
});
afterEach(() => jest.useRealTimers());Node's built-in test runner (node:test) ships its own mock-timers API since Node 20.4, mock.timers.enable({ apis: [...] }). Same idea, slightly different surface, and worth knowing about if you've moved off Jest/Vitest.
import { test, mock } from 'node:test';
import assert from 'node:assert/strict';
import { debounce } from '../src/debounce.js';
test('debounce fires after the delay', () => {
mock.timers.enable({ apis: ['setTimeout'] });
try {
const calls: string[] = [];
const debounced = debounce((s: string) => calls.push(s), 200);
debounced('hello');
mock.timers.tick(200);
assert.deepEqual(calls, ['hello']);
} finally {
mock.timers.reset();
}
});Two patterns to copy: the apis allowlist (don't fake what you don't need) and the try/finally around mock.timers.reset() (so a failed assertion doesn't leak a paused clock into the next test).
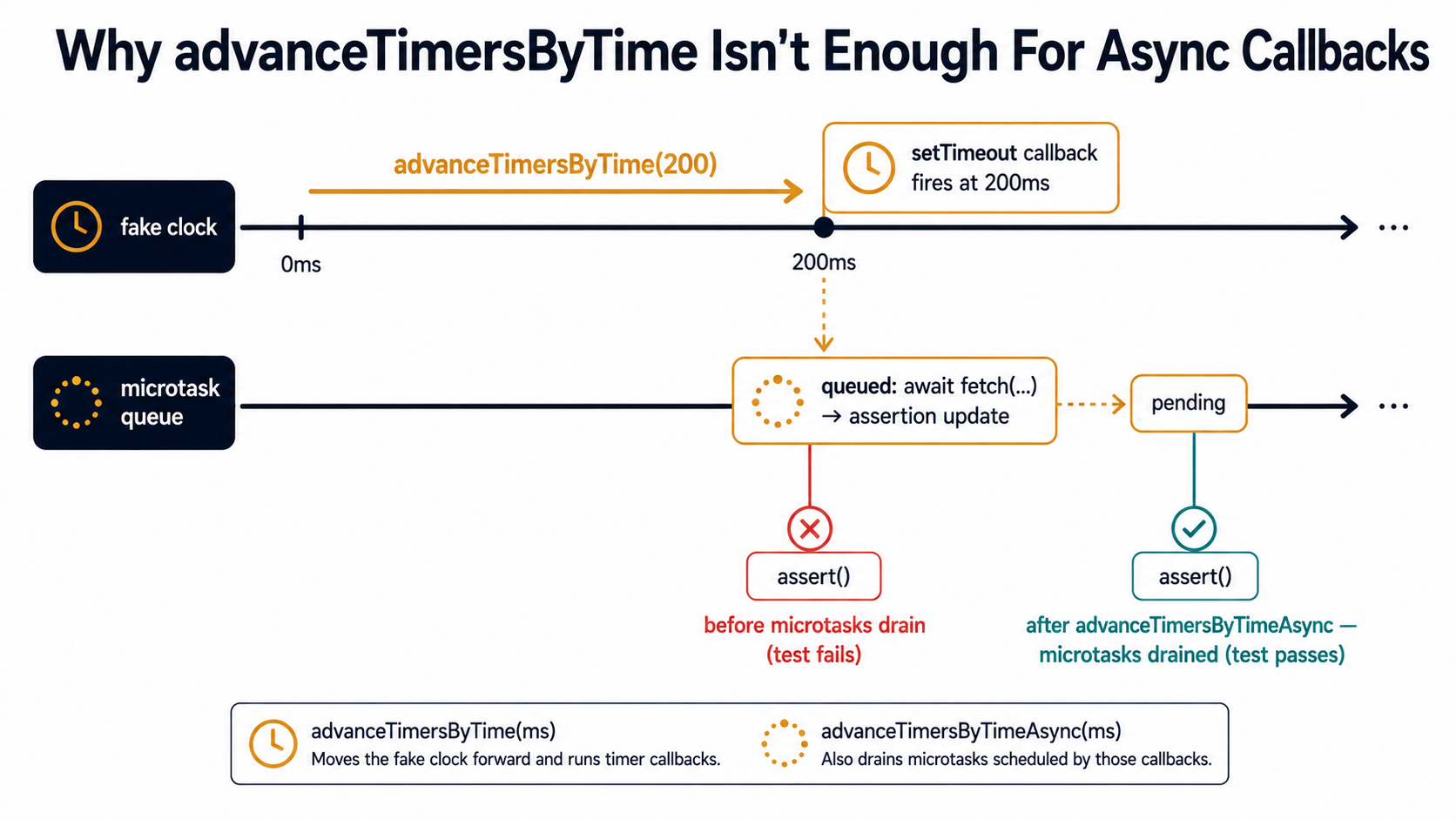
Promises, Microtasks, And The "Why Didn't It Wait" Problem
A lot of "this test is flaky" reports are actually "this test never awaited the thing." Async behaviour in JavaScript is layered, promises resolve on the microtask queue, which drains between every macrotask, but a microtask scheduled inside the awaited function doesn't always finish before the next line of test code runs. You have to be explicit.
The clearest case is when you mock a function that returns a promise. The mock resolves immediately, but "immediately" means "on the next microtask tick", and your assertion can run in the same tick where the mock was called.
import { describe, it, expect, vi } from 'vitest';
import { saveUser } from '../src/save-user.js';
describe('saveUser', () => {
it('persists then notifies', () => {
const repo = { insert: vi.fn().mockResolvedValue({ id: 1 }) };
const notifier = { onCreated: vi.fn() };
saveUser({ name: 'Ada' }, { repo, notifier });
expect(repo.insert).toHaveBeenCalled(); // passes — sync call
expect(notifier.onCreated).toHaveBeenCalled(); // fails — runs in .then()
});
});saveUser returned a promise. The test didn't await it. The notifier.onCreated call sits inside a .then() handler, scheduled on the microtask queue, and the assertion runs before that queue drains.
The fix is one keyword:
it('persists then notifies', async () => {
// ...same setup...
await saveUser({ name: 'Ada' }, { repo, notifier });
expect(repo.insert).toHaveBeenCalled();
expect(notifier.onCreated).toHaveBeenCalled();
});That's the easy case. The harder case is when the function under test doesn't return the promise, it schedules background work and returns synchronously by design.
export function enqueue(item: Item, deps: Deps) {
deps.transport.send(item)
.then(() => deps.log.info('sent', item.id))
.catch((err) => deps.log.error('send failed', err));
return { queued: true }; // returns immediately
}You can't await enqueue(...) because it returns a plain object. So how do you assert that log.info was called after transport.send resolved? The wrong answer is setTimeout(() => ..., 0). The right answer is to flush the microtask queue explicitly.
import { describe, it, expect, vi } from 'vitest';
import { enqueue } from '../src/queue.js';
// One reliable flush helper. Reuse across the suite.
const flushMicrotasks = () => new Promise<void>((r) => setImmediate(r));
describe('enqueue', () => {
it('logs after send resolves', async () => {
const transport = { send: vi.fn().mockResolvedValue(undefined) };
const log = { info: vi.fn(), error: vi.fn() };
enqueue({ id: 'abc' }, { transport, log });
await flushMicrotasks();
expect(transport.send).toHaveBeenCalled();
expect(log.info).toHaveBeenCalledWith('sent', 'abc');
});
});setImmediate runs after the current microtask queue drains. Awaiting a promise that resolves on setImmediate gives every pending .then() a chance to run. You'll sometimes see await new Promise(r => setTimeout(r, 0)) for the same purpose, it works, but setImmediate is fractionally more honest about its meaning ("after I/O callbacks") and doesn't interact with fake timers if you've installed them.
A second pattern, and the cleanest one when it works, is to expose a way for the code itself to signal completion. Make enqueue return both the synchronous result and a promise:
export function enqueue(item: Item, deps: Deps) {
const sent = deps.transport.send(item)
.then(() => deps.log.info('sent', item.id))
.catch((err) => deps.log.error('send failed', err));
return { queued: true, sent };
}Callers in production ignore sent. Tests await result.sent. The production behaviour doesn't change; the test no longer needs to guess about microtask draining. This is a "make the seam testable" move, not a hack, and it removes a whole class of flakes.
The third case is the trickiest: a function that schedules work on the microtask queue and on a timer, and the test cares about a specific order. This is where you need both advanceTimersByTimeAsync and the explicit flush, in that order. Advance the clock to fire the timer, then flush microtasks to let the timer's .then() chain drain. Get those two steps the wrong way around and the test reads correctly but still fails intermittently.
Race Conditions That Only Appear In CI
This is the category that gets a test added to the retry list. Local runs pass. CI passes nine times out of ten. The tenth time, one test in the middle of the file fails with an error that mentions a completely different piece of state.
The cause is almost always one of three things, and all three have the same root: a test that returned before its work was actually done, and the work resurfaced inside a later test.
Cause 1: an unawaited background promise. A test calls a function that fires off some background work, a metric push, a cache warm, a log flush. The test asserts on the synchronous return value and finishes. The background promise rejects, in a test six tests later, with UnhandledPromiseRejection: connection closed. The actual failing test had nothing to do with connections.
The fix is to never let production code "fire and forget" without a way for tests to await the side effect. The completion-promise pattern from the last section is one way. Dependency injection where the background work is a no-op in tests is another. In some cases, instrumentation, metrics, it's fine for the side effect to never resolve in tests, as long as it can be silenced cleanly with a stub.
Cause 2: a real timer escaping the test. Test A schedules setTimeout(doSomething, 50) and returns. The runner moves to Test B. 50ms later, doSomething runs in the middle of Test B's setup and corrupts a fixture. Test B fails. Test A passed.
The defence is twofold. In the production code, expose the timer handle so tests can cancel it:
export class Poller {
private handle?: NodeJS.Timeout;
start(interval: number, fn: () => void) {
this.handle = setInterval(fn, interval);
// unref so the handle doesn't keep Node alive in production either
this.handle.unref();
}
stop() {
if (this.handle) clearInterval(this.handle);
}
}In the tests, call stop() in afterEach. Or, use fake timers for everything that involves scheduling and never let a real timer be created in test mode at all.
Cause 3: shared module-level state. A module caches something at the top level, a database pool, a singleton config, a memoised result. Test A populates the cache. Test B asserts on a fresh state. Test A's leftover entry is still there, and Test B fails or, worse, passes for the wrong reason.
The cleanest fix is to make the cache injectable. The next-cleanest is to reset it explicitly in beforeEach. The worst fix is to randomise test order so the bug becomes invisible, except every CI run that fails will still surface it, in a different test each time, and you'll never find the source.
A practical guardrail: turn on process.on('unhandledRejection') in your test setup and fail the suite when one fires.
process.on('unhandledRejection', (reason) => {
// Fail the entire run loudly. Don't swallow.
console.error('Unhandled rejection in test run:', reason);
process.exit(1);
});This catches the unawaited background promise from Cause 1, and it's the single highest-leverage line you can add to a flaky suite. Most test runners will already do this for you in newer versions (Jest 29+, Vitest, node:test), but verify rather than assume, older configurations swallow rejections silently and you don't find out until the runtime upgrade.
EventEmitters, Streams, And The "Wait For The Event" Pattern
A lot of async tests in Node aren't about promises at all, they're about events. A server emits 'listening' when it's ready. A stream emits 'end' when it's done. A child process emits 'exit' when it terminates. Tests that assert on these need to wait for the event, not poll for it.
The naive version is to attach a listener and call the test runner's done callback:
it('starts listening', (done) => {
const server = createServer();
server.listen(0, () => {
expect(server.address()).not.toBeNull();
done();
});
});This works, but done-style tests have a problem: if your assertion throws, the error doesn't propagate cleanly, it surfaces as a timeout instead of as the actual expect failure. The signal-to-noise of the error message drops to nothing. And if you forget to call done on the unhappy path, the test hangs until the runner kills it.
The modern equivalent is events.once. It returns a promise that resolves on the next emission, or rejects if the emitter emits 'error' first.
import { once } from 'node:events';
import { createServer } from 'node:http';
import { describe, it, expect } from 'vitest';
it('starts listening', async () => {
const server = createServer();
server.listen(0);
await once(server, 'listening');
expect(server.address()).not.toBeNull();
server.close();
});Two things to notice. First, await once(...) gives you native promise behaviour, thrown assertions surface as failed assertions, not as timeouts. Second, server.close() runs at the end, which matters because a leaked listening server is a Cause 2 from the last section: it sits there in the next test's window and eats memory or, worse, holds an event-loop reference that keeps the test process alive past completion.
For streams, the same pattern works, await once(stream, 'end') for a readable stream, await finished(stream) from node:stream/promises for the more general "done in any way (end or error)" case.
import { finished } from 'node:stream/promises';
import { createReadStream } from 'node:fs';
it('reads the file fully', async () => {
const stream = createReadStream('fixtures/small.txt');
const chunks: Buffer[] = [];
stream.on('data', (chunk) => chunks.push(chunk));
await finished(stream);
expect(Buffer.concat(chunks).toString()).toBe('hello\n');
});finished is the right call here because it covers both the success path ('end') and the failure path ('error') without you having to wire both listeners by hand.
Always Clean Up, Even On Failure
If a test sets up a resource, a server, a database connection, a temp directory, a fake clock, a process listener, that resource has to be torn down when the test ends, including when the test throws partway through. The pattern that makes this boring is afterEach and try/finally, used together when you can't rely on the test runner.
import { afterEach, beforeEach, describe, it } from 'vitest';
import { startServer, stopServer } from '../src/test-utils.js';
describe('webhook delivery', () => {
let server: Awaited<ReturnType<typeof startServer>>;
beforeEach(async () => { server = await startServer(0); });
afterEach(async () => { await stopServer(server); });
it('delivers to the webhook URL', async () => {
// ...
});
});The bit that catches people is that afterEach runs even if the test fails, so if your teardown depends on state the failed test was supposed to set up, the teardown itself can throw and mask the original failure. Guard against that with optional chaining or a tracked-resources pattern, where you push every resource to an array and tear them all down with Promise.allSettled:
type Cleanup = () => Promise<void> | void;
export function trackedResources() {
const cleanups: Cleanup[] = [];
return {
track: (cleanup: Cleanup) => cleanups.push(cleanup),
async dispose() {
const results = await Promise.allSettled(
cleanups.reverse().map((fn) => Promise.resolve(fn())),
);
cleanups.length = 0;
const failed = results.filter((r) => r.status === 'rejected');
if (failed.length) throw new AggregateError(
failed.map((r) => (r as PromiseRejectedResult).reason),
'Resource cleanup failed',
);
},
};
}Use it from any test:
import { afterEach, beforeEach, it } from 'vitest';
import { trackedResources } from './helpers/resources.js';
const r = trackedResources();
afterEach(() => r.dispose());
it('does the thing', async () => {
const server = await startServer(0); r.track(() => stopServer(server));
const db = await openDb(); r.track(() => db.close());
// ...
});The reverse order matters, resources usually depend on each other (the DB pool depends on the network being up, the server depends on the DB), and tearing them down in the opposite order of construction avoids "the connection closed while I was trying to close the pool" cascades.
Use The Test Runner's Concurrency Knobs Honestly
Modern Node test runners default to running test files in parallel. That's almost always the right default, it's fast, it surfaces shared-state bugs, and it puts pressure on your isolation. But it also means your assumptions about "no two of these tests run at the same time" need to be enforced explicitly when they actually matter.
Two patterns worth knowing:
Run files in parallel, tests within a file in serial. This is the default for Jest and Vitest. The implication is that any state you mutate inside a file should be reset in beforeEach, but you generally don't have to worry about test order within a file. Across files, the assumption breaks, two test files running at the same time can hit the same database row, the same temp filename, the same port. Use unique identifiers per file (Math.random(), process.pid, a per-file UUID) rather than fixed names.
Run all tests sequentially when you have to. Sometimes the test really does need a global lock, a migration test, a "wipe the database and reseed" suite, a test of behaviour that depends on process.env mutations. Use vitest --no-file-parallelism or Jest's --runInBand. Don't sprinkle it.serial everywhere by default, the parallelism is doing real work for you, and going serial across the suite is a meaningful loss.
node:test defaults to running test files in parallel and tests within a file in serial too. The flag for sequential file execution is --test-concurrency=1. The principle is the same: parallelism is the default, serial is a deliberate choice you make when you can defend it.
A Short Checklist For The Next Async Test You Write
A handful of questions, asked before you write the assertion, catch most flakes before they exist:
- Does the function under test return a promise? If yes, is the test
asyncand is the callawaited? - Does the function schedule background work? If yes, do you have a way to await its completion, or are you draining microtasks explicitly?
- Are you using fake timers? If yes, did you call
advanceTimersByTimeAsyncand notadvanceTimersByTime? IsuseRealTimersinafterEach? - Does the test create any long-lived resource, server, timer, listener, connection? If yes, is teardown in
afterEach, and does it run even if the test threw? - Does the production code share module-level state? If yes, is that state reset between tests, or, better, injected per test?
- Is
unhandledRejectionconfigured to fail the run? If you have a flaky suite and you don't know which test is leaking, this single line will often point straight at the culprit.
None of these are clever. None of them require a new library. They're just the questions that the flaky-test version of the same code doesn't ask, and the boring-test version always does.
The Real Goal
Flaky tests aren't a feature of async code. They're a feature of tests that lie about being finished. Every pattern in this piece is a different way of being honest, explicit about what you're waiting for, explicit about what cleanup runs, explicit about which timer is faked and which is real.
The payoff is the boring kind. CI is green or red, and red means the code is broken, not that the test runner happened to schedule things in an unlucky order. New tests get added without anyone reaching for the retry plugin. The flaky-test channel goes quiet.
That's it. There's no fancier reward than that.





